
We all know there are three most important methods to maneuver packets throughout a community. Nevertheless, earlier than we are able to begin forwarding packets, somebody has to populate the forwarding tables within the intermediate gadgets or construct the sequence of nodes to traverse in supply routing.
Normally, whoever is chargeable for the contents of the forwarding tables should first uncover the community topology. Let’s begin there, utilizing the next community diagram as an instance the dialogue.
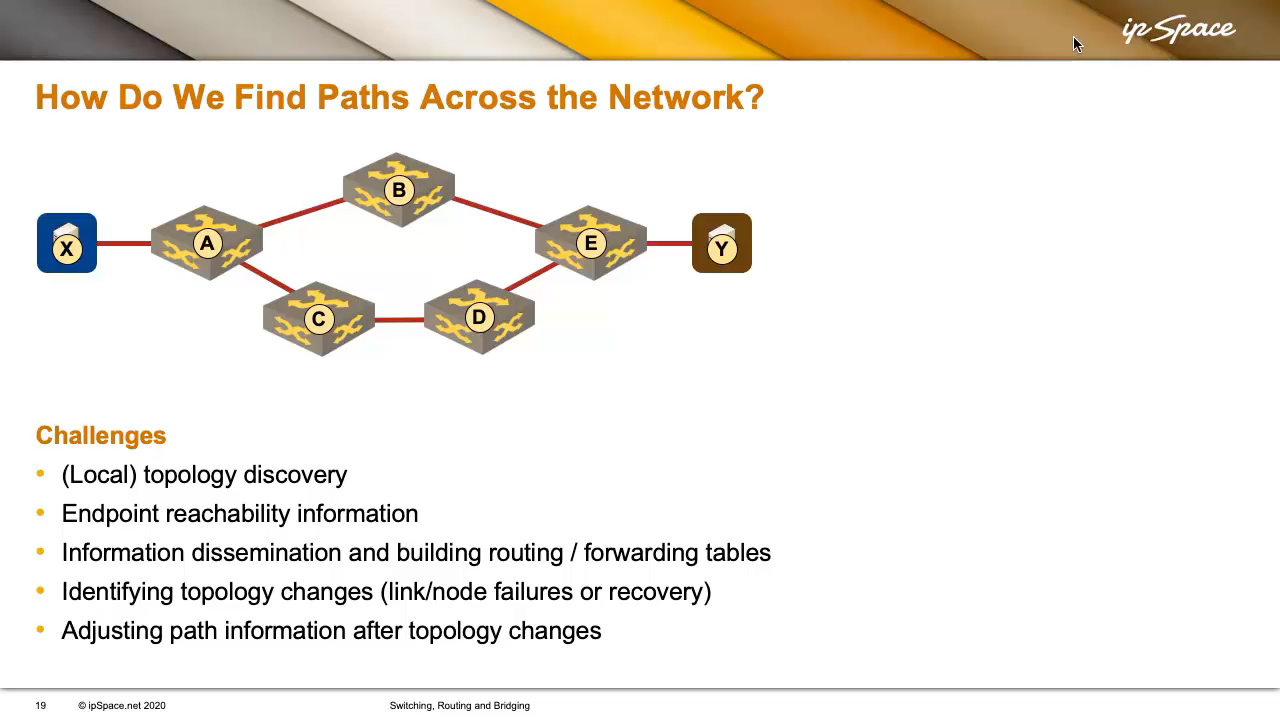
We will argue whether or not it’s essential to know your entire community topology or simply the native neighborhood, and there’s no right reply. After we get to routing protocols, you’ll see that with link-state protocols, all of the nodes—from A to E—keep a whole view of the community of their databases.
Alternatively, with distance-vector protocols, a node like C would solely learn about its rapid neighbors, A and D. It wouldn’t even know that B or E exist. However even in that case, C nonetheless must know at the very least its native topology—it should know who its neighbors are.
After discovering the community topology, we have to decide the areas of the endpoints. Suppose we’ve endpoints X and Y; somebody should uncover that X is on the left and Y is on the precise.
There are numerous methods to do this:
- static configuration: If A is an IP router, you’d configure a subnet on the interface related to X.
- information aircraft studying utilized in applied sciences like clear bridging. For instance, the second X sends a packet, A may say, “Oh, I’ve seen a packet from X, let me keep in mind that.”
- In ISO CLNP, X would ship Finish System Hellos or (as we mentioned within the addressing part), permitting A to study the place X is after which inform the remainder of the community.
- A may also take heed to ICMPv6 Neighbor Discovery messages, ARP requests, or DHCP replies to seek out out the hooked up IPv6/IPv4 endpoints.
The method of end-to-end path discovery often includes these steps:
- Uncover some native topology.
- Determine who’s related to whom.
- Mix and share this info with all related nodes.
- Construct the forwarding tables.
As soon as the community is up and operating, the paths throughout the community can change resulting from inevitable failures. For instance, suppose we’ve determined that the trail from X to Y is A → B → E. If the hyperlink between B and E fails (or B fails), we’ve an issue (if E fails, we’re out of luck it doesn’t matter what).
To deal with the link- or node failures, somebody must detect the failure, acknowledge that the topology has modified, decide how the change impacts forwarding choices, after which propagate that up to date info. Afterward, somebody wants to regulate the trail info accordingly.
For instance, after the failure of the B-E hyperlink, A should study that to succeed in Y, it ought to now go by way of C → D → E. There are numerous methods to realize this, most of them described within the Switching, Routing, and Bridging a part of the How Networks Actually Work webinar.
Arising subsequent: utilizing end-to-end paths in supply routing





{kind=link}