

Massive language fashions (LLMs) generate textual content step-by-step, which limits their capability to plan for duties requiring a number of reasoning steps, resembling structured writing or problem-solving. This lack of long-term planning impacts their coherence and decision-making in complicated eventualities. Some approaches consider varied alternate options earlier than making a alternative, which improves prediction precision. Nonetheless, they’ve increased computational prices and are susceptible to errors if future forecasts have been incorrect.
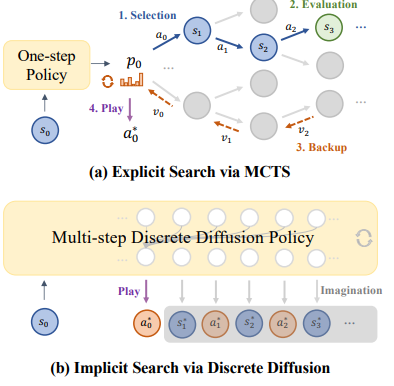
Obvious search algorithms like Monte Carlo Tree Search (MCTS) and beam search are well-liked in AI planning and decision-making however lack inherent limitations. They use repeated simulations of the long run, with rising computation prices and rendering them unsuitable for real-time programs. Additionally they depend upon a price mannequin to estimate each state, which, if incorrect, propagates the error alongside the search. Since longer predictions create extra errors, these errors construct up and reduce determination accuracy. That is significantly problematic in sophisticated duties necessitating long-term planning, the place it turns into difficult to take care of correct foresight, leading to inferior outcomes.
To mitigate these points, researchers from The College of Hong Kong, Shanghai Jiaotong College, Huawei Noah’s Ark Lab, and Shanghai AI Laboratory proposed DIFFUSEARCH. This discrete diffusion-based framework eliminates specific search algorithms like MCTS. As an alternative of counting on expensive search processes, DIFFUSEARCH trains the coverage to immediately predict and make the most of future representations, refining predictions iteratively utilizing diffusion fashions. Integrating the world mannequin and coverage right into a single framework reduces computational overhead whereas bettering effectivity and accuracy in long-term planning.
The framework trains the mannequin utilizing supervised studying, leveraging Stockfish as an oracle to label board states from chess video games. Completely different future representations are examined, with the action-state (s-asa) technique chosen for simplicity and effectivity. Moderately than immediately predicting future sequences, the mannequin makes use of discrete diffusion modeling, making use of self-attention and iterative denoising to enhance motion predictions progressively. DIFFUSEARCH avoids expensive marginalization over future states throughout inference by immediately sampling from the skilled mannequin. A simple-first decoding technique prioritizes extra predictable tokens for denoising, enhancing accuracy.
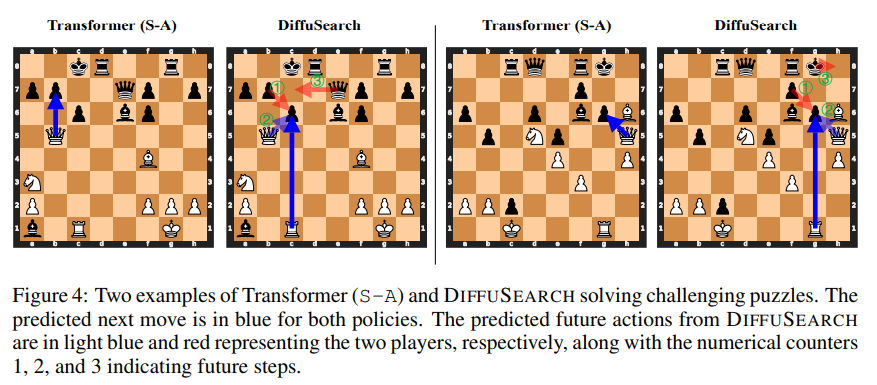
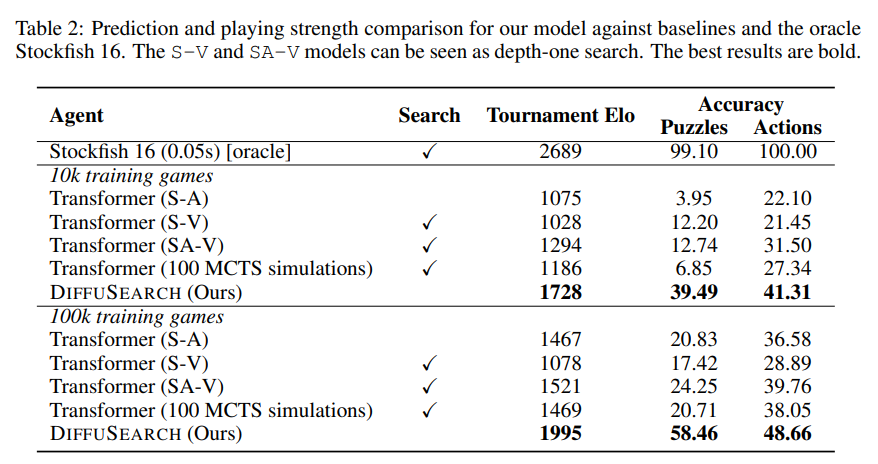
Researchers evaluated DIFFUSEARCH towards three transformer-based baselines: State-Motion (S-A), State-Worth (S-V), and Motion-Worth (SA-V) fashions skilled utilizing behavioral cloning, value-based decision-making, and authorized motion comparability, respectively. Utilizing a dataset of 100k chess video games, with states encoded in FEN format and actions in UCI notation, they applied GPT-2-based fashions with an Adam optimizer, a 3e-4 studying fee, a batch dimension of 1024, an 8-layer structure (7M parameters), a horizon of 4, and diffusion timesteps set to twenty. Evaluations included motion accuracy, puzzle accuracy, and Elo rankings from a 6000-game inside event. DIFFUSEARCH outperformed S-A by 653 Elo and 19% in motion accuracy and exceeded SA-V regardless of utilizing 20 occasions fewer information information. Discrete diffusion with linear λt achieved the very best accuracy (41.31%), surpassing autoregressive and Gaussian strategies. DIFFUSEARCH retained predictive capability in future strikes, although accuracy declined over steps, and efficiency improved with extra consideration layers and refined decoding. Positioned as an implicit search technique, it demonstrated competitiveness with specific MCTS-based approaches.
In abstract, the proposed mannequin established that implicit search through discrete diffusion might successfully substitute specific search and enhance chess decision-making. The mannequin surpassed searchless and specific insurance policies and confirmed its potential to be taught future-imitative methods. Though utilizing an exterior oracle and a restricted information set, the mannequin indicated future prospects for enchancment via self-play and long-context modeling. Extra typically, this technique might be utilized to enhance next-token prediction in language fashions. As a place to begin for additional investigation, it varieties a foundation for investigating implicit search in AI planning and decision-making.
Take a look at the Paper, and GitHub Web page. All credit score for this analysis goes to the researchers of this undertaking. Additionally, be happy to comply with us on Twitter and don’t neglect to hitch our 80k+ ML SubReddit.
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Know-how, Kharagpur. He’s a Information Science and Machine studying fanatic who needs to combine these main applied sciences into the agricultural area and clear up challenges.





{kind=link}