

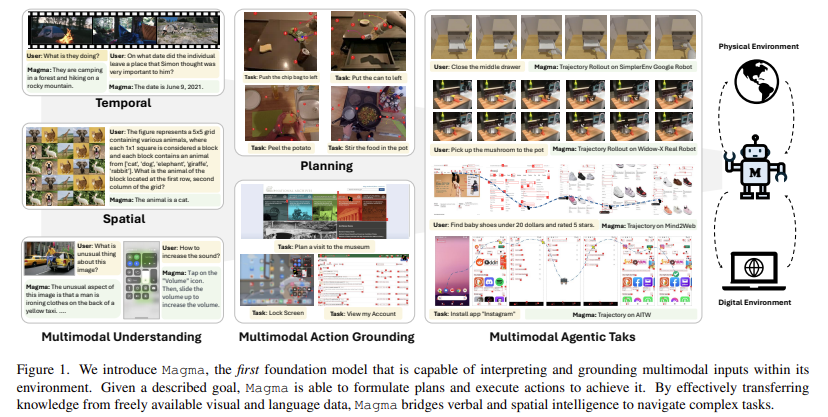
Multimodal AI brokers are designed to course of and combine varied information sorts, similar to pictures, textual content, and movies, to carry out duties in digital and bodily environments. They’re utilized in robotics, digital assistants, and consumer interface automation, the place they should perceive and act primarily based on advanced multimodal inputs. These programs purpose to bridge verbal and spatial intelligence by leveraging deep studying strategies, enabling interactions throughout a number of domains.
AI programs typically concentrate on vision-language understanding or robotic manipulation however battle to mix these capabilities right into a single mannequin. Many AI fashions are designed for domain-specific duties, similar to UI navigation in digital environments or bodily manipulation in robotics, limiting their generalization throughout totally different functions. The problem lies in growing a unified mannequin to grasp and act throughout a number of modalities, making certain efficient decision-making in structured and unstructured environments.
Present Imaginative and prescient-Language-Motion (VLA) fashions try to deal with multimodal duties by pretraining on giant datasets of vision-language pairs adopted by motion trajectory information. Nevertheless, these fashions sometimes lack adaptability throughout totally different environments. Examples embrace Pix2Act and WebGUM, which excel in UI navigation, and OpenVLA and RT-2, that are optimized for robotic manipulation. These fashions typically require separate coaching processes and fail to generalize throughout each digital and bodily environments. Additionally, typical multimodal fashions battle with integrating spatial and temporal intelligence, limiting their skill to carry out advanced duties autonomously.
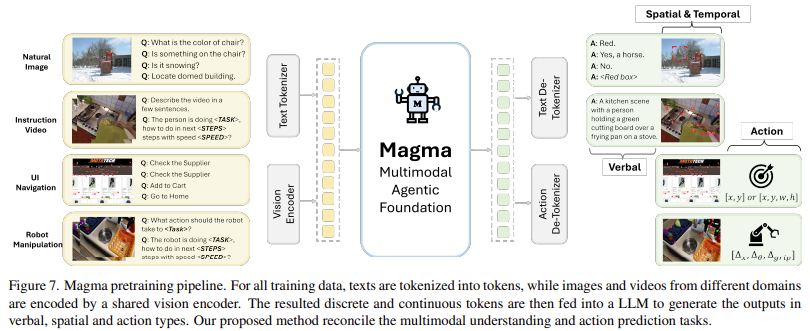
Researchers from Microsoft Analysis, the College of Maryland, the College of Wisconsin-Madison KAIST, and the College of Washington launched Magma, a basis mannequin designed to unify multimodal understanding with motion execution, enabling AI brokers to operate seamlessly in digital and bodily environments. Magma is designed to beat the shortcomings of current VLA fashions by incorporating a sturdy coaching methodology that integrates multimodal understanding, motion grounding, and planning. Magma is educated utilizing a various dataset comprising 39 million samples, together with pictures, movies, and robotic motion trajectories. It incorporates two novel strategies,
- Set-of-Mark (SoM): SoM permits the mannequin to label actionable visible objects, similar to buttons in UI environments
- Hint-of-Mark (ToM): ToM permits it to trace object actions over time and plan future actions accordingly
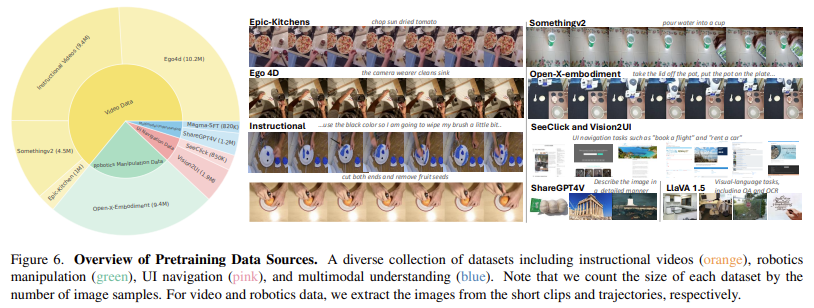
Magma employs a mix of deep studying architectures and large-scale pretraining to optimize its efficiency throughout a number of domains. The mannequin makes use of a ConvNeXt-XXL imaginative and prescient spine to course of pictures and movies, whereas an LLaMA-3-8B language mannequin handles textual inputs. This structure permits Magma to combine vision-language understanding with motion execution seamlessly. It’s educated on a curated dataset that features UI navigation duties from SeeClick and Vision2UI, robotic manipulation datasets from Open-X-Embodiment, and tutorial movies from sources like Ego4D, One thing-One thing V2, and Epic-Kitchen. By leveraging SoM and ToM, Magma can successfully study motion grounding from UI screenshots and robotics information whereas enhancing its skill to foretell future actions primarily based on noticed visible sequences. Throughout coaching, the mannequin processes as much as 2.7 million UI screenshots, 970,000 robotic trajectories, and over 25 million video samples to make sure strong multimodal studying.
In zero-shot UI navigation duties, Magma achieved a component choice accuracy of 57.2%, outperforming fashions like GPT-4V-OmniParser and SeeClick. In robotic manipulation duties, Magma attained successful price of 52.3% in Google Robotic duties and 35.4% in Bridge simulations, considerably surpassing OpenVLA, which solely achieved 31.7% and 15.9% in the identical benchmarks. The mannequin additionally carried out exceptionally properly in multimodal understanding duties, reaching 80.0% accuracy in VQA v2, 66.5% in TextVQA, and 87.4% in POPE evaluations. Magma additionally demonstrated sturdy spatial reasoning capabilities, scoring 74.8% on the BLINK dataset and 80.1% on the Visible Spatial Reasoning (VSR) benchmark. In video question-answering duties, Magma achieved an accuracy of 88.6% on IntentQA and 72.9% on NextQA, additional highlighting its skill to course of temporal info successfully.
A number of Key Takeaways emerge from the Analysis on Magma:
- Magma was educated on 39 million multimodal samples, together with 2.7 million UI screenshots, 970,000 robotic trajectories, and 25 million video samples.
- The mannequin combines imaginative and prescient, language, and motion in a unified framework, overcoming the restrictions of domain-specific AI fashions.
- SoM permits correct labeling of clickable objects, whereas ToM permits monitoring object motion over time, bettering long-term planning capabilities.
- Magma achieved a 57.2% accuracy price in component choice in UI duties, a 52.3% success price in robotic manipulation, and an 80.0% accuracy price in VQA duties.
- Magma outperformed current AI fashions by over 19.6% in spatial reasoning benchmarks and improved by 28% over earlier fashions in video-based reasoning.
- Magma demonstrated superior generalization throughout a number of duties with out requiring extra fine-tuning, making it a extremely adaptable AI agent.
- Magma’s capabilities can improve decision-making and execution in robotics, autonomous programs, UI automation, digital assistants, and industrial AI.
Try the Paper and Mission Web page. All credit score for this analysis goes to the researchers of this undertaking. Additionally, be at liberty to comply with us on Twitter and don’t overlook to affix our 75k+ ML SubReddit.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.




{kind=link}