

A couple of years in the past, I fell into the world of anime from which I’d by no means escape. As my watchlist was rising thinner and thinner, discovering the following greatest anime turned tougher and tougher. There are such a lot of hidden gems on the market, however how do I uncover them? That’s after I thought—why not let Machine Studying sensei do the onerous work? Sounds thrilling, proper?
In our digital period, advice techniques are the silent leisure heroes that energy our every day on-line experiences. Whether or not it entails suggesting tv collection, creating a customized music playlist, or recommending merchandise primarily based on shopping historical past, these algorithms function within the background to enhance consumer engagement.
This information walks you thru constructing a production-ready anime advice engine that runs 24/7 with out the necessity for conventional cloud platforms. With hands-on use circumstances, code snippets, and an in depth exploration of the structure, you’ll be outfitted to construct and deploy your individual advice engine.
Studying Goals
- Perceive the whole knowledge processing and mannequin coaching workflows to make sure effectivity and scalability.
- Construct and deploy an enticing user-friendly advice system on Hugging Face Areas with a dynamic interface.
- Achieve hands-on expertise in growing end-to-end advice engines utilizing machine studying approaches resembling SVD, collaborative filtering and content-based filtering.
- Seamlessly containerize your undertaking utilizing Docker for constant deployment throughout totally different environments.
- Mix varied advice methods inside one interactive software to ship personalised suggestions.
This text was revealed as part of the Information Science Blogathon.
Anime Advice System with Hugging Face: Information Assortment
The muse of any advice system lies in high quality knowledge. For this undertaking, datasets had been sourced from Kaggle after which saved within the Hugging Face Datasets Hub for streamlined entry and integration. The first datasets used embody:
- Animes: A dataset detailing anime titles and related metadata.
- Anime_UserRatings: Consumer ranking knowledge for every anime.
- UserRatings: Common consumer scores offering insights into viewing habits.
Pre-requisites for Anime Advice App
Earlier than we start, guarantee that you’ve got accomplished the next steps:
1. Signal Up and Log In
- Go to Hugging Face and create an account for those who haven’t already.
- Log in to your Hugging Face account to entry the Areas part.
2. Create a New Area
- Navigate to the “Areas” part out of your profile or dashboard.
- Click on on the “Create New Area” button.
- Present a singular title in your area and select the “Streamlit” possibility for the app interface.
- Set your area to public or personal primarily based in your choice.
3. Clone the Area Repository
- After creating the Area, you’ll be redirected to the repository web page in your new area.
- Clone the repository to your native machine utilizing Git with the next command:
git clone https://huggingface.co/areas/your-username/your-space-name4. Set Up the Digital Surroundings
- Navigate to your undertaking listing and create a brand new digital setting utilizing Python’s built-in venv device.
# Creating the Digital setting
## For macOS and Linux:
python3 -m venv env
## For Home windows:
python -m venv env
# Activation the setting
## For macOS and Linux:
supply env/bin/activate
## For Home windows:
.envScriptsactivate5. Set up Dependencies
- Within the cloned repository, create a necessities.txt file that lists all of the dependencies your app requires (e.g., Streamlit, pandas, and so on.).
- Set up the dependencies utilizing the command:
pip set up -r necessities.txtEarlier than diving into the code, it’s important to grasp how the varied elements of the system work together. Try the beneath undertaking structure.
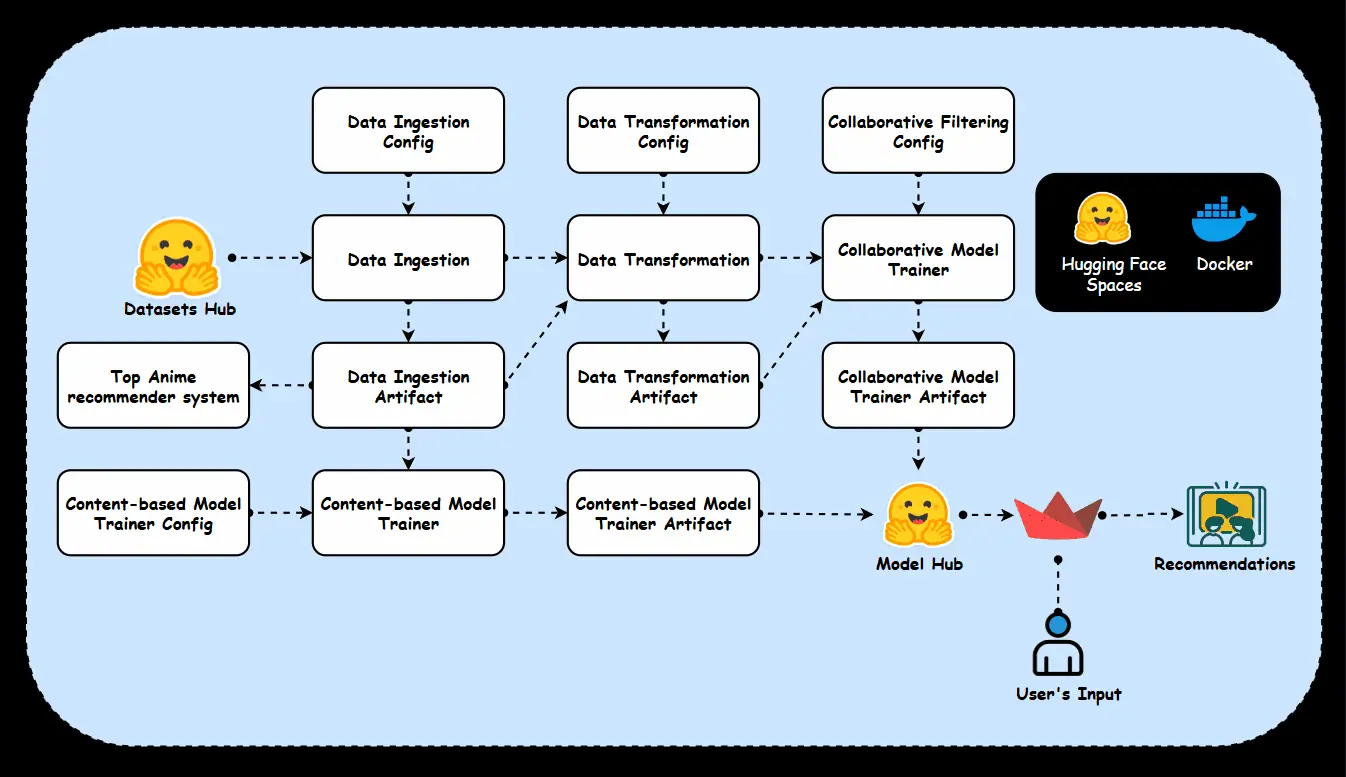
Folder Construction
This undertaking adopts a modular folder construction designed to align with business requirements, making certain scalability and maintainability.
ANIME-RECOMMENDATION-SYSTEM/ # Undertaking listing
├── anime_recommender/ # Primary package deal containing all of the modules
│ │── __init__.py # Package deal initialization
│ │
│ ├── elements/ # Core elements of the advice system
│ │ │── __init__.py # Package deal initialization
│ │ │── collaborative_recommender.py # Collaborative filtering mannequin
│ │ │── content_based_recommender.py # Content material-based filtering mannequin
│ │ │── data_ingestion.py # Fetches and masses knowledge
│ │ │── data_transformation.py # Preprocesses and transforms the information
│ │ │── top_anime_recommenders.py # Filters prime animes
│ │
│ ├── fixed/
│ │ │── __init__.py # Shops fixed values used throughout the undertaking
│ │
│ ├── entity/ # Defines structured entities like configs and artifacts
│ │ │── __init__.py
│ │ │── artifact_entity.py # Information constructions for mannequin artifacts
│ │ │── config_entity.py # Configuration parameters and settings
│ │
│ ├── exception/ # Customized exception dealing with
│ │ │── __init__.py
│ │ │── exception.py # Handles errors and exceptions
│ │
│ ├── loggers/ # Logging and monitoring setup
│ │ │── __init__.py
│ │ │── logging.py # Configures log settings
│ │
│ ├── model_trainer/ # Mannequin coaching scripts
│ │ │── __init__.py
│ │ │── collaborative_modelling.py # Practice collaborative filtering mannequin
│ │ │── content_based_modelling.py # Practice content-based mannequin
│ │ │── top_anime_filtering.py # Filters prime animes primarily based on scores
│ │
│ ├── pipelines/ # Finish-to-end ML pipelines
│ │ │── __init__.py
│ │ │── training_pipeline.py # Coaching pipeline
│ │
│ ├── utils/ # Utility features
│ │ │── __init__.py
│ │ ├── main_utils/
│ │ │ │── __init__.py
│ │ │ │── utils.py # Utility features for particular processing
├── notebooks/ # Jupyter notebooks for EDA and experimentation
│ ├── EDA.ipynb # Exploratory Information Evaluation
│ ├── final_ARS.ipynb # Ultimate implementation pocket book
├── .gitattributes # Git configuration for dealing with file codecs
├── .gitignore # Specifies recordsdata to disregard in model management
├── app.py # Primary Streamlit app
├── Dockerfile # Docker configuration for containerization
├── README.md # Undertaking documentation
├── necessities.txt # Dependencies and libraries
├── run_pipeline.py # Runs the whole coaching pipeline
├── setup.py # Setup script for package deal set upConstants
The fixed/__init__.py file defines all important constants, resembling file paths, listing names, and mannequin filenames. These constants standardize configurations throughout the information ingestion, transformation, and mannequin coaching phases. This ensures consistency, maintainability, and quick access to key undertaking configurations.
"""Defining frequent fixed variables for coaching pipeline"""
PIPELINE_NAME: str = "AnimeRecommender"
ARTIFACT_DIR: str = "Artifacts"
ANIME_FILE_NAME: str = "Animes.csv"
RATING_FILE_NAME:str = "UserRatings.csv"
MERGED_FILE_NAME:str = "Anime_UserRatings.csv"
ANIME_FILE_PATH:str = "krishnaveni76/Animes"
RATING_FILE_PATH:str = "krishnaveni76/UserRatings"
ANIMEUSERRATINGS_FILE_PATH:str = "krishnaveni76/Anime_UserRatings"
MODELS_FILEPATH = "krishnaveni76/anime-recommendation-models"
"""Information Ingestion associated fixed begin with DATA_INGESTION VAR NAME"""
DATA_INGESTION_DIR_NAME: str = "data_ingestion"
DATA_INGESTION_FEATURE_STORE_DIR: str = "feature_store"
DATA_INGESTION_INGESTED_DIR: str = "ingested"
"""Information Transformation associated fixed begin with DATA_VALIDATION VAR NAME"""
DATA_TRANSFORMATION_DIR:str = "data_transformation"
DATA_TRANSFORMATION_TRANSFORMED_DATA_DIR:str = "remodeled"
"""Mannequin Coach associated fixed begin with MODEL TRAINER VAR NAME"""
MODEL_TRAINER_DIR_NAME: str = "trained_models"
MODEL_TRAINER_COL_TRAINED_MODEL_DIR: str = "collaborative_recommenders"
MODEL_TRAINER_SVD_TRAINED_MODEL_NAME: str = "svd.pkl"
MODEL_TRAINER_ITEM_KNN_TRAINED_MODEL_NAME: str = "itembasedknn.pkl"
MODEL_TRAINER_USER_KNN_TRAINED_MODEL_NAME: str = "userbasedknn.pkl"
MODEL_TRAINER_CON_TRAINED_MODEL_DIR:str = "content_based_recommenders"
MODEL_TRAINER_COSINESIMILARITY_MODEL_NAME:str = "cosine_similarity.pkl"Utils
The utils/main_utils/utils.py file incorporates utility features for operations resembling saving/loading knowledge, exporting dataframes, saving fashions, and importing fashions to Hugging Face. These reusable features streamline processes all through the undertaking.
def export_data_to_dataframe(dataframe: pd.DataFrame, file_path: str) -> pd.DataFrame:
dir_path = os.path.dirname(file_path)
os.makedirs(dir_path, exist_ok=True)
dataframe.to_csv(file_path, index=False, header=True)
return dataframe
def load_csv_data(file_path: str) -> pd.DataFrame:
df = pd.read_csv(file_path)
return df
def save_model(mannequin: object, file_path: str) -> None:
os.makedirs(os.path.dirname(file_path), exist_ok=True)
with open(file_path, "wb") as file_obj:
joblib.dump(mannequin, file_obj)
def load_object(file_path: str) -> object:
if not os.path.exists(file_path):
error_msg = f"The file: {file_path} doesn't exist."
elevate Exception(error_msg)
with open(file_path, "rb") as file_obj:
return joblib.load(file_obj)
def upload_model_to_huggingface(model_path: str, repo_id: str, filename: str):
api = HfApi()
api.upload_file(path_or_fileobj=model_path,path_in_repo=filename,=repo_id,repo_type="mannequin" ) Configuration Setup
The entity/config_entity.py file holds configuration particulars for various phases of the coaching pipeline. This consists of paths for knowledge ingestion, transformation, and mannequin coaching for each collaborative and content-based advice techniques. These configurations guarantee a structured and arranged workflow all through the undertaking.
class TrainingPipelineConfig:
def __init__(self, timestamp=datetime.now()):
timestamp = timestamp.strftime("%m_percentd_percentY_percentH_percentM_percentS")
self.pipeline_name = PIPELINE_NAME
self.artifact_dir = os.path.be a part of(ARTIFACT_DIR, timestamp)
self.model_dir=os.path.be a part of("final_model")
self.timestamp: str = timestamp
class DataIngestionConfig:
def __init__(self, training_pipeline_config: TrainingPipelineConfig):
self.data_ingestion_dir: str = os.path.be a part of(training_pipeline_config.artifact_dir, DATA_INGESTION_DIR_NAME)
self.feature_store_anime_file_path: str = os.path.be a part of(self.data_ingestion_dir, DATA_INGESTION_FEATURE_STORE_DIR, ANIME_FILE_NAME)
self.feature_store_userrating_file_path: str = os.path.be a part of(self.data_ingestion_dir, DATA_INGESTION_FEATURE_STORE_DIR, RATING_FILE_NAME)
self.anime_filepath: str = ANIME_FILE_PATH
self.rating_filepath: str = RATING_FILE_PATH
class DataTransformationConfig:
def __init__(self,training_pipeline_config:TrainingPipelineConfig):
self.data_transformation_dir:str = os.path.be a part of(training_pipeline_config.artifact_dir,DATA_TRANSFORMATION_DIR)
self.merged_file_path:str = os.path.be a part of(self.data_transformation_dir,DATA_TRANSFORMATION_TRANSFORMED_DATA_DIR,MERGED_FILE_NAME)
class CollaborativeModelConfig:
def __init__(self,training_pipeline_config:TrainingPipelineConfig):
self.model_trainer_dir:str = os.path.be a part of(training_pipeline_config.artifact_dir,MODEL_TRAINER_DIR_NAME)
self.svd_trained_model_file_path:str = os.path.be a part of(self.model_trainer_dir,MODEL_TRAINER_COL_TRAINED_MODEL_DIR,MODEL_TRAINER_SVD_TRAINED_MODEL_NAME)
self.user_knn_trained_model_file_path:str = os.path.be a part of(self.model_trainer_dir,MODEL_TRAINER_COL_TRAINED_MODEL_DIR,MODEL_TRAINER_USER_KNN_TRAINED_MODEL_NAME)
self.item_knn_trained_model_file_path:str = os.path.be a part of(self.model_trainer_dir,MODEL_TRAINER_COL_TRAINED_MODEL_DIR,MODEL_TRAINER_ITEM_KNN_TRAINED_MODEL_NAME)
class ContentBasedModelConfig:
def __init__(self,training_pipeline_config:TrainingPipelineConfig):
self.model_trainer_dir:str = os.path.be a part of(training_pipeline_config.artifact_dir,MODEL_TRAINER_DIR_NAME)
self.cosine_similarity_model_file_path:str = os.path.be a part of(self.model_trainer_dir,MODEL_TRAINER_CON_TRAINED_MODEL_DIR,MODEL_TRAINER_COSINESIMILARITY_MODEL_NAME)Artifacts entity
The entity/artifact_entity.py file defines courses for artifacts generated at varied phases. These artifacts assist monitor and handle intermediate outputs resembling processed datasets and educated fashions.
@dataclass
class DataIngestionArtifact:
feature_store_anime_file_path:str
feature_store_userrating_file_path:str
@dataclass
class DataTransformationArtifact:
merged_file_path:str
@dataclass
class CollaborativeModelArtifact:
svd_file_path:str
item_based_knn_file_path:str
user_based_knn_file_path:str
@dataclass
class ContentBasedModelArtifact:
cosine_similarity_model_file_path:strAdvice System – Mannequin Coaching
On this undertaking, we implement three sorts of advice techniques to boost the anime advice expertise:
- Collaborative Advice System
- Content material-Based mostly Advice System
- High Anime Advice System
Every method performs a singular function in delivering personalised suggestions. By breaking down every part, we are going to achieve a deeper understanding.
1. Collaborative Advice System
This Collaborative Advice System suggests gadgets to customers primarily based on the preferences and behaviours of different customers. It operates beneath the belief that if two customers have proven comparable pursuits prior to now, they’re more likely to have comparable preferences sooner or later. This method is extensively utilized in platforms like Netflix, Amazon, and anime advice engines to offer personalised options. In our case, we apply this advice approach to determine customers with comparable preferences and counsel anime primarily based on their shared pursuits.
We are going to observe the beneath workflow to construct our advice system. Every step is fastidiously structured to make sure seamless integration, beginning with knowledge assortment, adopted by transformation, and eventually coaching a mannequin to generate significant suggestions.
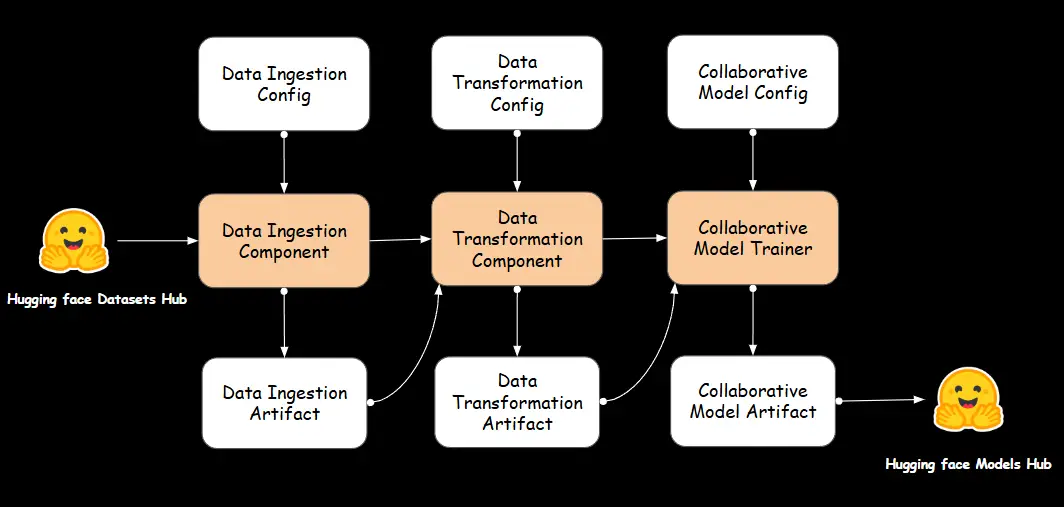
A. Information Ingestion
Information ingestion is the method of gathering, importing, and transferring knowledge from varied sources into an information storage system or pipeline for additional processing and evaluation. It’s a essential first step in any data-driven software, because it permits the system to entry and work with the uncooked knowledge required to generate insights, practice fashions, or carry out different duties.
Information Ingestion Part
We outline a DataIngestion class in elements/data_ingestion.py file which handles the method of fetching datasets from Hugging Face Datasets Hub, and loading them into Pandas DataFrames. It makes use of DataIngestionConfig to acquire the required file paths and configurations for the ingestion course of. The ingest_data methodology masses the anime and consumer ranking datasets, exports them as CSV recordsdata to the function retailer, and returns a DataIngestionArtifact containing the paths of the ingested recordsdata. This class encapsulates the information ingestion logic, making certain that knowledge is correctly fetched, saved, and made accessible for additional phases of the pipeline.
class DataIngestion:
def __init__(self, data_ingestion_config: DataIngestionConfig):
self.data_ingestion_config = data_ingestion_config
def fetch_data_from_huggingface(self, dataset_path: str, break up: str = None) -> pd.DataFrame:
dataset = load_dataset(dataset_path, break up=break up)
df = pd.DataFrame(dataset['train'])
return df
def ingest_data(self) -> DataIngestionArtifact:
anime_df = self.fetch_data_from_huggingface(self.data_ingestion_config.anime_filepath)
rating_df = self.fetch_data_from_huggingface(self.data_ingestion_config.rating_filepath)
export_data_to_dataframe(anime_df, file_path=self.data_ingestion_config.feature_store_anime_file_path)
export_data_to_dataframe(rating_df, file_path=self.data_ingestion_config.feature_store_userrating_file_path)
dataingestionartifact = DataIngestionArtifact(
feature_store_anime_file_path=self.data_ingestion_config.feature_store_anime_file_path,
feature_store_userrating_file_path=self.data_ingestion_config.feature_store_userrating_file_path
)
return dataingestionartifact B. Information Transformation
Information transformation is the method of changing uncooked knowledge right into a format or construction that’s appropriate for evaluation, modelling, or integration right into a system. It’s a essential step within the knowledge preprocessing pipeline, particularly for machine studying, because it helps be sure that the information is clear, constant, and formatted in a means that fashions can successfully use.
Information Transformation Part
In elements/data_transformation.py file, we implement the DataTransformation class to handle the transformation of uncooked knowledge right into a cleaned and merged dataset, prepared for additional processing. The category consists of strategies to learn knowledge from CSV recordsdata, merge two datasets (anime and scores), clear and filter the merged knowledge. Particularly, the merge_data methodology combines the datasets primarily based on a standard column (anime_id), whereas the clean_filter_data methodology handles duties like changing lacking values, changing columns to numeric varieties, filtering rows primarily based on circumstances, and eradicating pointless columns. The initiate_data_transformation methodology coordinates the whole transformation course of, storing the ensuing remodeled dataset within the specified location utilizing DataTransformationArtifact entity.
class DataTransformation:
def __init__(self,data_ingestion_artifact:DataIngestionArtifact,data_transformation_config:DataTransformationConfig):
self.data_ingestion_artifact = data_ingestion_artifact
self.data_transformation_config = data_transformation_config
@staticmethod
def read_data(file_path)->pd.DataFrame:
return pd.read_csv(file_path)
@staticmethod
def merge_data(anime_df: pd.DataFrame, rating_df: pd.DataFrame) -> pd.DataFrame:
merged_df = pd.merge(rating_df, anime_df, on="anime_id", how="inside")
return merged_df
@staticmethod
def clean_filter_data(merged_df: pd.DataFrame) -> pd.DataFrame:
merged_df['average_rating'].substitute('UNKNOWN', np.nan)
merged_df['average_rating'] = pd.to_numeric(merged_df['average_rating'], errors="coerce")
merged_df['average_rating'].fillna(merged_df['average_rating'].median())
merged_df = merged_df[merged_df['average_rating'] > 6]
cols_to_drop = [ 'username', 'overview', 'type', 'episodes', 'producers', 'licensors', 'studios', 'source', 'rank', 'popularity', 'favorites', 'scored by', 'members' ]
cleaned_df = merged_df.copy()
cleaned_df.drop(columns=cols_to_drop, inplace=True)
return cleaned_df
def initiate_data_transformation(self)->DataTransformationArtifact:
anime_df = DataTransformation.read_data(self.data_ingestion_artifact.feature_store_anime_file_path)
rating_df = DataTransformation.read_data(self.data_ingestion_artifact.feature_store_userrating_file_path)
merged_df = DataTransformation.merge_data(anime_df, rating_df)
transformed_df = DataTransformation.clean_filter_data(merged_df)
export_data_to_dataframe(transformed_df, self.data_transformation_config.merged_file_path)
data_transformation_artifact = DataTransformationArtifact( merged_file_path=self.data_transformation_config.merged_file_path)
return data_transformation_artifact C. Collaborative Recommender
The Collaborative filtering is extensively utilized in advice techniques, the place predictions are made primarily based on user-item interactions moderately than specific options of the gadgets.
Collaborative Modelling
The CollaborativeAnimeRecommender class is designed to offer personalised anime suggestions utilizing collaborative filtering strategies. It employs three totally different fashions:
- Singular Worth Decomposition (SVD) :– A matrix factorization approach that learns latent components representing consumer preferences and anime traits, enabling personalised suggestions primarily based on previous scores.
- Merchandise-Based mostly Okay-Nearest Neighbors (KNN) :– Finds comparable anime titles primarily based on consumer ranking patterns, recommending exhibits just like a given anime.
- Consumer-Based mostly Okay-Nearest Neighbors (KNN) :– Identifies customers with comparable preferences and suggests anime that like-minded customers have loved.
The category processes uncooked consumer scores, constructs interplay matrices, and trains the fashions to generate tailor-made suggestions. The recommender supplies predictions for particular person customers, recommends comparable anime titles, and suggests new exhibits primarily based on consumer similarity. By leveraging collaborative filtering strategies, this method enhances consumer expertise by providing personalised and related anime suggestions.
class CollaborativeAnimeRecommender:
def __init__(self, df):
self.df = df
self.svd = None
self.knn_item_based = None
self.knn_user_based = None
self.prepare_data()
def prepare_data(self):
self.df = self.df.drop_duplicates()
reader = Reader(rating_scale=(1, 10))
self.knowledge = Dataset.load_from_df(self.df[['user_id', 'anime_id', 'rating']], reader)
self.anime_pivot = self.df.pivot_table(index='title', columns="user_id", values="ranking").fillna(0)
self.user_pivot = self.df.pivot_table(index='user_id', columns="title", values="ranking").fillna(0)
def train_svd(self):
self.svd = SVD()
cross_validate(self.svd, self.knowledge, cv=5)
trainset = self.knowledge.build_full_trainset()
self.svd.match(trainset)
def train_knn_item_based(self):
item_user_matrix = csr_matrix(self.anime_pivot.values)
self.knn_item_based = NearestNeighbors(metric="cosine", algorithm='brute')
self.knn_item_based.match(item_user_matrix)
def train_knn_user_based(self):
user_item_matrix = csr_matrix(self.user_pivot.values)
self.knn_user_based = NearestNeighbors(metric="cosine", algorithm='brute')
self.knn_user_based.match(user_item_matrix)
def print_unique_user_ids(self):
unique_user_ids = self.df['user_id'].distinctive()
return unique_user_ids
def get_svd_recommendations(self, user_id, n=10, svd_model=None)-> pd.DataFrame:
svd_model = svd_model or self.svd
if svd_model is None:
elevate ValueError("SVD mannequin will not be supplied or educated.")
if user_id not in self.df['user_id'].distinctive():
return f"Consumer ID '' not discovered within the dataset."
anime_ids = self.df['anime_id'].distinctive()
predictions = [(anime_id, svd_model.predict(user_id, anime_id).est) for anime_id in anime_ids]
predictions.type(key=lambda x: x[1], reverse=True)
recommended_anime_ids = [pred[0] for pred in predictions[:n]]
recommended_anime = self.df[self.df['anime_id'].isin(recommended_anime_ids)].drop_duplicates(subset="anime_id")
recommended_anime = recommended_anime.head(n)
return pd.DataFrame({ 'Anime Identify': recommended_anime['name'].values, 'Genres': recommended_anime['genres'].values, 'Picture URL': recommended_anime['image url'].values, 'Ranking': recommended_anime['average_rating'].values})
def get_item_based_recommendations(self, anime_name, n_recommendations=10, knn_item_model=None):
knn_item_based = knn_item_model or self.knn_item_based
if knn_item_based is None:
elevate ValueError("Merchandise-based KNN mannequin will not be supplied or educated.")
if anime_name not in self.anime_pivot.index:
return f"Anime title '{anime_name}' not discovered within the dataset."
query_index = self.anime_pivot.index.get_loc(anime_name)
distances, indices = knn_item_based.kneighbors( self.anime_pivot.iloc[query_index, :].values.reshape(1, -1), n_neighbors=n_recommendations + 1 )
suggestions = []
for i in vary(1, len(distances.flatten())):
anime_title = self.anime_pivot.index[indices.flatten()[i]]
distance = distances.flatten()[i]
suggestions.append((anime_title, distance))
recommended_anime_titles = [rec[0] for rec in suggestions]
filtered_df = self.df[self.df['name'].isin(recommended_anime_titles)].drop_duplicates(subset="title")
filtered_df = filtered_df.head(n_recommendations)
return pd.DataFrame({ 'Anime Identify': filtered_df['name'].values, 'Picture URL': filtered_df['image url'].values, 'Genres': filtered_df['genres'].values, 'Ranking': filtered_df['average_rating'].values })
def get_user_based_recommendations(self, user_id, n_recommendations=10, knn_user_model=None)-> pd.DataFrame:
knn_user_based = knn_user_model or self.knn_user_based
if knn_user_based is None:
elevate ValueError("Consumer-based KNN mannequin will not be supplied or educated.")
user_id = float(user_id)
if user_id not in self.user_pivot.index:
return f"Consumer ID '' not discovered within the dataset."
user_idx = self.user_pivot.index.get_loc(user_id)
distances, indices = knn_user_based.kneighbors( self.user_pivot.iloc[user_idx, :].values.reshape(1, -1), n_neighbors=n_recommendations + 1 )
user_rated_anime = set(self.user_pivot.columns[self.user_pivot.iloc[user_idx, :] > 0])
all_neighbor_ratings = []
for i in vary(1, len(distances.flatten())):
neighbor_idx = indices.flatten()[i]
neighbor_rated_anime = self.user_pivot.iloc[neighbor_idx, :]
neighbor_ratings = neighbor_rated_anime[neighbor_rated_anime > 0]
all_neighbor_ratings.prolong(neighbor_ratings.index)
anime_counter = Counter(all_neighbor_ratings)
suggestions = [(anime, count) for anime, count in anime_counter.items() if anime not in user_rated_anime]
suggestions.type(key=lambda x: x[1], reverse=True)
recommended_anime_titles = [rec[0] for rec in suggestions[:n_recommendations]]
filtered_df = self.df[self.df['name'].isin(recommended_anime_titles)].drop_duplicates(subset="title")
filtered_df = filtered_df.head(n_recommendations)
return pd.DataFrame({ 'Anime Identify': filtered_df['name'].values, 'Picture URL': filtered_df['image url'].values, 'Genres': filtered_df['genres'].values, 'Ranking': filtered_df['average_rating'].values }) Collaborative Mannequin Coach Part
The CollaborativeModelTrainer automates the coaching, saving, and deployment of the fashions. It ensures that educated fashions are saved domestically and likewise uploaded to Hugging Face, making them simply accessible for producing suggestions.
class CollaborativeModelTrainer:
def __init__(self, collaborative_model_trainer_config: CollaborativeModelConfig, data_transformation_artifact: DataTransformationArtifact):
self.collaborative_model_trainer_config = collaborative_model_trainer_config
self.data_transformation_artifact = data_transformation_artifact
def initiate_model_trainer(self) -> CollaborativeModelArtifact:
df = load_csv_data(self.data_transformation_artifact.merged_file_path)
recommender = CollaborativeAnimeRecommender(df)
# Practice and save SVD mannequin
recommender.train_svd()
save_model(mannequin=recommender.svd,file_path= self.collaborative_model_trainer_config.svd_trained_model_file_path)
upload_model_to_huggingface(
model_path=self.collaborative_model_trainer_config.svd_trained_model_file_path,
repo_id=MODELS_FILEPATH,
filename=MODEL_TRAINER_SVD_TRAINED_MODEL_NAME
)
svd_model = load_object(self.collaborative_model_trainer_config.svd_trained_model_file_path)
svd_recommendations = recommender.get_svd_recommendations(user_id=436, n=10, svd_model=svd_model)
# Practice and save Merchandise-Based mostly KNN mannequin
recommender.train_knn_item_based()
save_model(mannequin=recommender.knn_item_based, file_path=self.collaborative_model_trainer_config.item_knn_trained_model_file_path)
upload_model_to_huggingface(
model_path=self.collaborative_model_trainer_config.item_knn_trained_model_file_path,
repo_id=MODELS_FILEPATH,
filename=MODEL_TRAINER_ITEM_KNN_TRAINED_MODEL_NAME
)
item_knn_model = load_object(self.collaborative_model_trainer_config.item_knn_trained_model_file_path)
item_based_recommendations = recommender.get_item_based_recommendations(
anime_name="One Piece", n_recommendations=10, knn_item_model=item_knn_model
)
# Practice and save Consumer-Based mostly KNN mannequin
recommender.train_knn_user_based()
save_model(mannequin=recommender.knn_user_based,file_path= self.collaborative_model_trainer_config.user_knn_trained_model_file_path)
upload_model_to_huggingface(
model_path=self.collaborative_model_trainer_config.user_knn_trained_model_file_path,
repo_id=MODELS_FILEPATH,
filename=MODEL_TRAINER_USER_KNN_TRAINED_MODEL_NAME
)
user_knn_model = load_object(self.collaborative_model_trainer_config.user_knn_trained_model_file_path)
user_based_recommendations = recommender.get_user_based_recommendations(
user_id=817, n_recommendations=10, knn_user_model=user_knn_model
)
return CollaborativeModelArtifact(
svd_file_path=self.collaborative_model_trainer_config.svd_trained_model_file_path,
item_based_knn_file_path=self.collaborative_model_trainer_config.item_knn_trained_model_file_path,
user_based_knn_file_path=self.collaborative_model_trainer_config.user_knn_trained_model_file_path
) 2. Content material-Based mostly Advice System
This content-based advice system suggests gadgets to customers by analyzing the attributes of things resembling style, key phrases, or descriptions to generate suggestions primarily based on similarity.
For instance, in an anime advice system, if a consumer enjoys a specific anime, the mannequin identifies comparable anime primarily based on attributes like style, voice actors, or themes. Methods resembling TF-IDF (Time period Frequency-Inverse Doc Frequency), cosine similarity, and machine studying fashions assist in rating and suggesting related gadgets.
In contrast to collaborative filtering, which depends upon consumer interactions, content-based filtering is impartial of different customers’ preferences, making it efficient even in circumstances with fewer consumer interactions (chilly begin drawback).
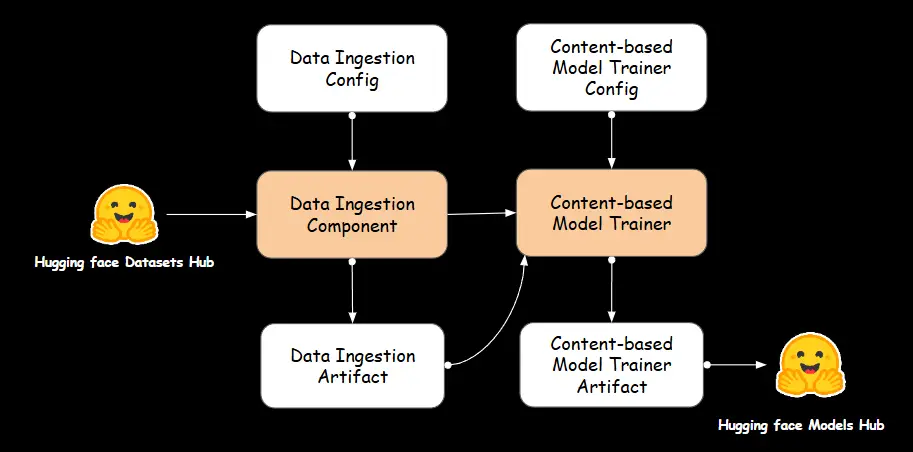
A. Information Ingestion
We use the artifacts from the information ingestion part mentioned earlier to coach the content-based recommender.
B. Content material-Based mostly Recommender
The Content material-Based mostly recommender is chargeable for coaching advice fashions that analyze merchandise attributes to generate personalised options. It processes knowledge, extracts related options, and builds fashions that determine similarities between gadgets primarily based on their content material.
Content material-Based mostly Modelling
The ContentBasedRecommender class leverages TF-IDF (Time period Frequency-Inverse Doc Frequency) and Cosine Similarity to counsel anime primarily based on their style similarities. The mannequin first processes the dataset by eradicating lacking values and changing textual style info into numerical function vectors utilizing TF-IDF vectorization. It then computes the cosine similarity between anime titles to measure their content material similarity. The educated mannequin is saved and later used to offer personalised suggestions by retrieving essentially the most comparable anime primarily based on a given title.
class ContentBasedRecommender:
def __init__(self, df):
self.df = df.dropna()
self.indices = pd.Sequence(self.df.index, index=self.df['name']).drop_duplicates()
self.tfv = TfidfVectorizer( min_df=3, strip_accents="unicode", analyzer="phrase", token_pattern=r'w{1,}', ngram_range=(1, 3), stop_words="english" )
self.tfv_matrix = self.tfv.fit_transform(self.df['genres'])
self.cosine_sim = cosine_similarity(self.tfv_matrix, self.tfv_matrix)
def save_model(self, model_path):
os.makedirs(os.path.dirname(model_path), exist_ok=True)
with open(model_path, 'wb') as f:
joblib.dump((self.tfv, self.cosine_sim), f)
def get_rec_cosine(self, title, model_path, n_recommendations=5):
with open(model_path, 'rb') as f:
self.tfv, self.cosine_sim = joblib.load(f)
if self.df is None:
elevate ValueError("The DataFrame will not be loaded, can't make suggestions.")
if title not in self.indices.index:
return f"Anime title '{title}' not discovered within the dataset."
idx = self.indicesHow to Construct an Anime Advice System?
cosinesim_scores = record(enumerate(self.cosine_sim[idx]))
cosinesim_scores = sorted(cosinesim_scores, key=lambda x: x[1], reverse=True)[1:n_recommendations + 1]
anime_indices = [i[0] for i in cosinesim_scores]
return pd.DataFrame({ 'Anime title': self.df['name'].iloc[anime_indices].values, 'Picture URL': self.df['image url'].iloc[anime_indices].values, 'Genres': self.df['genres'].iloc[anime_indices].values, 'Ranking': self.df['average_rating'].iloc[anime_indices].values }) Content material-Based mostly Mannequin Coach Part
The ContentBasedModelTrainer class is chargeable for automating the coaching and deployment of a content-based advice mannequin. It masses the processed anime dataset from the information ingestion artifact, initializes the ContentBasedRecommender, and trains it utilizing TF-IDF vectorization and cosine similarity. The educated mannequin is then saved and uploaded to Hugging Face.
class ContentBasedModelTrainer:
def __init__(self, content_based_model_trainer_config: ContentBasedModelConfig, data_ingestion_artifact: DataIngestionArtifact):
self.content_based_model_trainer_config = content_based_model_trainer_config
self.data_ingestion_artifact = data_ingestion_artifact
def initiate_model_trainer(self) -> ContentBasedModelArtifact:
df = load_csv_data(self.data_ingestion_artifact.feature_store_anime_file_path)
recommender = ContentBasedRecommender(df=df )
recommender.save_model(model_path=self.content_based_model_trainer_config.cosine_similarity_model_file_path)
upload_model_to_huggingface(
model_path=self.content_based_model_trainer_config.cosine_similarity_model_file_path,
repo_id=MODELS_FILEPATH,
filename=MODEL_TRAINER_COSINESIMILARITY_MODEL_NAME
)
cosine_recommendations = recommender.get_rec_cosine(title="One Piece", model_path=self.content_based_model_trainer_config.cosine_similarity_model_file_path, n_recommendations=10)
content_model_trainer_artifact = ContentBasedModelArtifact( cosine_similarity_model_file_path=self.content_based_model_trainer_config.cosine_similarity_model_file_path )
return content_model_trainer_artifact3. High Anime Advice System
It is not uncommon for newcomers to anime to hunt out the preferred titles first. This prime anime advice system is designed to assist these new to the anime world simply uncover fashionable, extremely rated, and top-ranked anime multi functional place through the use of easy sorting and filtering.
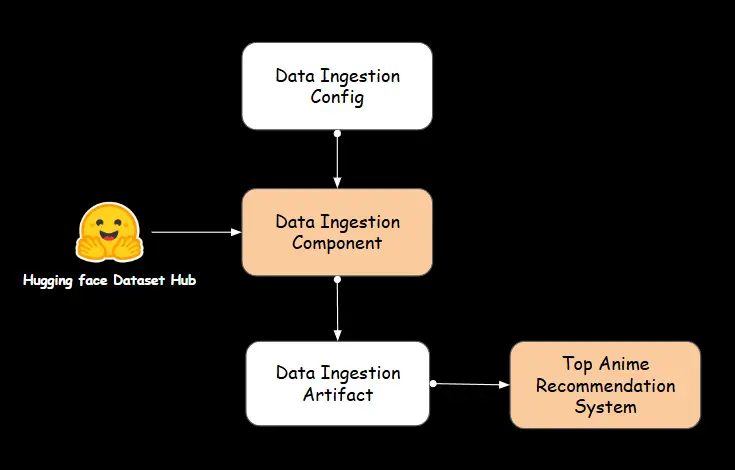
A. Information Ingestion
We make the most of the artifacts from the beforehand mentioned knowledge ingestion part on this advice system.
B. High Anime Recommender Part
High anime filtering
The PopularityBasedFiltering class is chargeable for rating and sorting anime utilizing predefined popularity-based parameters. It analyzes the dataset by evaluating attributes resembling ranking, variety of favorites, group dimension, and rating place. The category consists of specialised features to extract top-performing anime inside every class, making certain a structured method to filtering. Moreover, it manages lacking knowledge and refines the output for readability. By offering data-driven insights, this class performs an important function in figuring out fashionable and highly-rated anime for advice functions.
class PopularityBasedFiltering:
def __init__(self, df):
self.df = df
self.df['average_rating'] = pd.to_numeric(self.df['average_rating'], errors="coerce")
self.df['average_rating'].fillna(self.df['average_rating'].median())
def popular_animes(self, n=10):
sorted_df = self.df.sort_values(by=['popularity'], ascending=True)
top_n_anime = sorted_df.head(n)
return self._format_output(top_n_anime)
def top_ranked_animes(self, n=10):
self.df['rank'] = self.df['rank'].substitute('UNKNOWN', np.nan).astype(float)
df_filtered = self.df[self.df['rank'] > 1]
sorted_df = df_filtered.sort_values(by=['rank'], ascending=True)
top_n_anime = sorted_df.head(n)
return self._format_output(top_n_anime)
def overall_top_rated_animes(self, n=10):
sorted_df = self.df.sort_values(by=['average_rating'], ascending=False)
top_n_anime = sorted_df.head(n)
return self._format_output(top_n_anime)
def favorite_animes(self, n=10):
sorted_df = self.df.sort_values(by=['favorites'], ascending=False)
top_n_anime = sorted_df.head(n)
return self._format_output(top_n_anime)
def top_animes_members(self, n=10):
sorted_df = self.df.sort_values(by=['members'], ascending=False)
top_n_anime = sorted_df.head(n)
return self._format_output(top_n_anime)
def popular_anime_among_members(self, n=10):
sorted_df = self.df.sort_values(by=['members', 'average_rating'], ascending=[False, False]).drop_duplicates(subset="title")
popular_animes = sorted_df.head(n)
return self._format_output(popular_animes)
def top_avg_rated(self, n=10):
self.df['average_rating'] = pd.to_numeric(self.df['average_rating'], errors="coerce")
median_rating = self.df['average_rating'].median()
self.df['average_rating'].fillna(median_rating)
top_animes = ( self.df.drop_duplicates(subset="title").nlargest(n, 'average_rating')[['name', 'average_rating', 'image url', 'genres']] )
return self._format_output(top_animes)
def _format_output(self, anime_df):
return pd.DataFrame({ 'Anime title': anime_df['name'].values, 'Picture URL': anime_df['image url'].values, 'Genres': anime_df['genres'].values, 'Ranking': anime_df['average_rating'].values })High anime recommenders
The PopularityBasedRecommendor class is chargeable for recommending anime primarily based on totally different reputation metrics. It makes use of an anime dataset saved in feature_store_anime_file_path, which was a DataIngestionArtifact. The category integrates the PopularityBasedFiltering class to generate anime suggestions based on varied filtering standards, resembling top-ranked anime, hottest selections, group favorites, and highest-rated exhibits. By deciding on a particular filter_type, customers can retrieve the most effective match primarily based on their most well-liked standards.
class PopularityBasedRecommendor:
def __init__(self,data_ingestion_artifact = DataIngestionArtifact):
self.data_ingestion_artifact = data_ingestion_artifact
def initiate_model_trainer(self,filter_type:str):
df = load_csv_data(self.data_ingestion_artifact.feature_store_anime_file_path)
recommender = PopularityBasedFiltering(df)
if filter_type == 'popular_animes':
popular_animes = recommender.popular_animes(n =10)
elif filter_type == 'top_ranked_animes':
top_ranked_animes = recommender.top_ranked_animes(n =10)
elif filter_type == 'overall_top_rated_animes':
overall_top_rated_animes = recommender.overall_top_rated_animes(n =10)
elif filter_type == 'favorite_animes':
favorite_animes = recommender.favorite_animes(n =10)
elif filter_type == 'top_animes_members':
top_animes_members = recommender.top_animes_members(n = 10)
elif filter_type == 'popular_anime_among_members':
popular_anime_among_members = recommender.popular_anime_among_members(n =10)
elif filter_type == 'top_avg_rated':
top_avg_rated = recommender.top_avg_rated(n =10) Coaching Pipeline
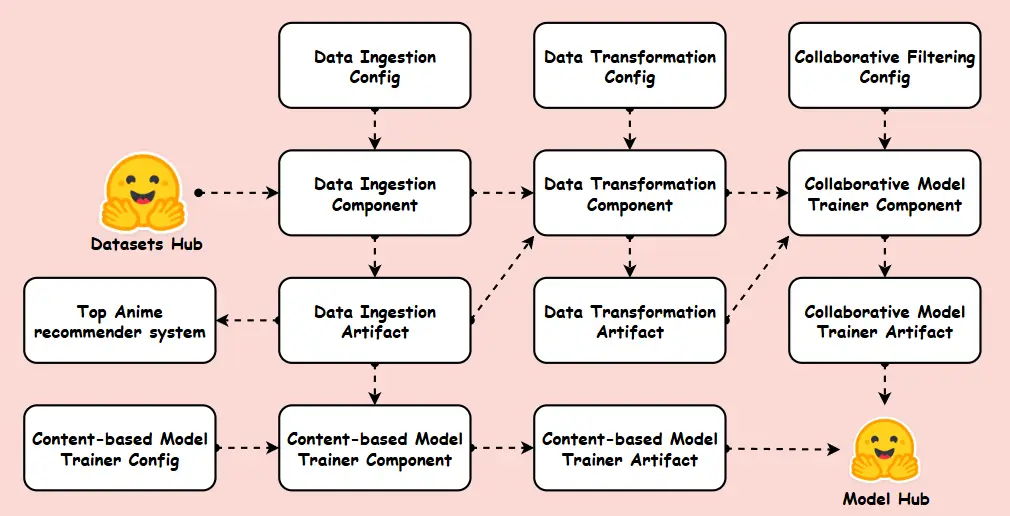
This Machine Studying Coaching Pipeline is designed to automate and streamline the method of constructing recommender fashions effectively. The pipeline follows a structured workflow, starting with knowledge ingestion from Hugging face, adopted by knowledge transformation to preprocess and put together the information for mannequin coaching. It incorporates totally different modelling strategies, resembling collaborative filtering, content-based approaches and Recognition-based filtering, making certain optimum efficiency. The ultimate educated fashions are saved in a Mannequin Hub, enabling seamless deployment and steady refinement. This structured method ensures scalability, effectivity, and reproducibility in machine studying workflows.
class TrainingPipeline:
def __init__(self):
self.training_pipeline_config = TrainingPipelineConfig()
def start_data_ingestion(self) -> DataIngestionArtifact:
data_ingestion_config = DataIngestionConfig(self.training_pipeline_config)
data_ingestion = DataIngestion(data_ingestion_config=data_ingestion_config)
data_ingestion_artifact = data_ingestion.ingest_data()
return data_ingestion_artifact
def start_data_transformation(self, data_ingestion_artifact: DataIngestionArtifact) -> DataTransformationArtifact:
data_transformation_config = DataTransformationConfig(self.training_pipeline_config)
data_transformation = DataTransformation(
data_ingestion_artifact=data_ingestion_artifact,
data_transformation_config=data_transformation_config
)
data_transformation_artifact = data_transformation.initiate_data_transformation()
return data_transformation_artifact
def start_collaborative_model_training(self, data_transformation_artifact: DataTransformationArtifact) -> CollaborativeModelArtifact:
collaborative_model_config = CollaborativeModelConfig(self.training_pipeline_config)
collaborative_model_trainer = CollaborativeModelTrainer(
collaborative_model_trainer_config=collaborative_model_config,
data_transformation_artifact=data_transformation_artifact )
collaborative_model_trainer_artifact = collaborative_model_trainer.initiate_model_trainer()
return collaborative_model_trainer_artifact
def start_content_based_model_training(self, data_ingestion_artifact: DataIngestionArtifact) -> ContentBasedModelArtifact:
content_based_model_config = ContentBasedModelConfig(self.training_pipeline_config)
content_based_model_trainer = ContentBasedModelTrainer(
content_based_model_trainer_config=content_based_model_config,
data_ingestion_artifact=data_ingestion_artifact )
content_based_model_trainer_artifact = content_based_model_trainer.initiate_model_trainer()
return content_based_model_trainer_artifact
def start_popularity_based_filtering(self, data_ingestion_artifact: DataIngestionArtifact):
filtering = PopularityBasedRecommendor(data_ingestion_artifact=data_ingestion_artifact)
suggestions = filtering.initiate_model_trainer(filter_type="popular_animes")
return suggestions
def run_pipeline(self):
# Information Ingestion
data_ingestion_artifact = self.start_data_ingestion()
# Content material-Based mostly Mannequin Coaching
content_based_model_trainer_artifact = self.start_content_based_model_training(data_ingestion_artifact)
# Recognition-Based mostly Filtering
popularity_recommendations = self.start_popularity_based_filtering(data_ingestion_artifact)
# Information Transformation
data_transformation_artifact = self.start_data_transformation(data_ingestion_artifact)
# Collaborative Mannequin Coaching
collaborative_model_trainer_artifact = self.start_collaborative_model_training(data_transformation_artifact)Now that we’ve accomplished creating the pipeline, run the training_pipeline.py file utilizing the beneath code to view the artifacts generated within the earlier steps.
python training_pipeline.py Streamlit App
The advice software is constructed utilizing Streamlit, a light-weight and interactive framework for creating data-driven net apps. It’s deployed on Hugging Face Areas, permitting customers to discover and work together with the anime advice system seamlessly. This setup supplies an intuitive UI for locating anime suggestions in actual time. Every time you push new adjustments, Hugging Face will redeploy your app mechanically.
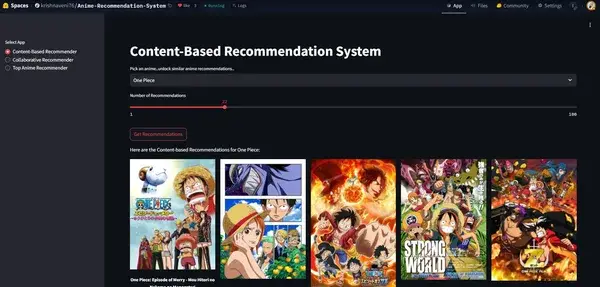
Docker Integration for Deployment
The Dockerfile units up a light-weight Python setting utilizing the official Python 3.10 slim-buster picture. It configures the working listing, copies software recordsdata, and installs dependencies from necessities.txt. Lastly, it exposes port 8501 and runs the Streamlit app, making it accessible inside the containerized setting.
# Use the official Python picture as a base
FROM python:3.10-slim-buster
# Set the working listing within the container
WORKDIR /app
# Copy the app recordsdata into the container
COPY . .
# Set up required packages
RUN pip set up -r necessities.txt
# Expose the port that Streamlit makes use of
EXPOSE 8501
# Run the Streamlit app
CMD ["streamlit", "run", "app.py", "--server.port=8501", "--server.address=0.0.0.0"] Key Takeaways
- We’ve got designed an environment friendly, end-to-end pipeline that ensures clean knowledge movement from ingestion to advice, making the system scalable, strong, and production-ready.
- New customers obtain trending anime options by way of a popularity-based engine, whereas returning customers get hyper-personalized picks by way of collaborative filtering fashions.
- By deploying on Hugging Face Areas with mannequin versioning, you obtain cost-free productionization with out paying any AWS/GCP payments whereas sustaining scalability!
- The system leverages Docker for containerization, making certain constant environments throughout totally different deployments.
- Constructed utilizing Streamlit, the app supplies a clear, dynamic, and fascinating consumer expertise, making anime discovery enjoyable and intuitive.
The media proven on this article will not be owned by Analytics Vidhya and is used on the Creator’s discretion.
Conclusion
Congratulations! You will have accomplished constructing the Advice app very quickly. From buying knowledge and preprocessing it to mannequin coaching and deployment, this undertaking highlights the ability of getting issues on the market into the world! However maintain up… we’re not executed but! 💥 There’s an entire lot extra enjoyable to come back! You’re now able to construct on one thing even cooler, like a Film Advice app!
That is just the start of our journey collectively, so buckle up—there are numerous extra thrilling tasks forward! Let’s continue learning and constructing!
Ceaselessly Requested Questions
Ans. Completely! Swap the dataset, modify style weights in constants.py, and voilà – you’ve bought a Squid Sport or Marvel Recommender very quickly!
Ans. Sure! A “Shock Me” button will be simply added utilizing random.alternative(), serving to customers uncover hidden anime gems randomly!
Ans. Their free tier handles ~10K month-to-month visits. In the event you hit Demon Slayer ranges of recognition, improve to PRO ($9/month) for precedence servers.
Good day! I am a passionate AI and Machine Studying fanatic presently exploring the thrilling realms of Deep Studying, MLOps, and Generative AI. I get pleasure from diving into new tasks and uncovering progressive strategies that push the boundaries of expertise. I will be sharing guides, tutorials, and undertaking insights primarily based alone experiences, so we will be taught and develop collectively. Be a part of me on this journey as we discover, experiment, and construct superb options on this planet of AI and past!
A couple of years in the past, I fell into the world of anime from which I’d by no means escape. As my watchlist was rising thinner and thinner, discovering the following greatest anime turned tougher and tougher. There are such a lot of hidden gems on the market, however how do I uncover them? That’s after I thought—why not let Machine Studying sensei do the onerous work? Sounds thrilling, proper?
In our digital period, advice techniques are the silent leisure heroes that energy our every day on-line experiences. Whether or not it entails suggesting tv collection, creating a customized music playlist, or recommending merchandise primarily based on shopping historical past, these algorithms function within the background to enhance consumer engagement.
This information walks you thru constructing a production-ready anime advice engine that runs 24/7 with out the necessity for conventional cloud platforms. With hands-on use circumstances, code snippets, and an in depth exploration of the structure, you’ll be outfitted to construct and deploy your individual advice engine.
Studying Goals
- Perceive the whole knowledge processing and mannequin coaching workflows to make sure effectivity and scalability.
- Construct and deploy an enticing user-friendly advice system on Hugging Face Areas with a dynamic interface.
- Achieve hands-on expertise in growing end-to-end advice engines utilizing machine studying approaches resembling SVD, collaborative filtering and content-based filtering.
- Seamlessly containerize your undertaking utilizing Docker for constant deployment throughout totally different environments.
- Mix varied advice methods inside one interactive software to ship personalised suggestions.
This text was revealed as part of the Information Science Blogathon.
Anime Advice System with Hugging Face: Information Assortment
The muse of any advice system lies in high quality knowledge. For this undertaking, datasets had been sourced from Kaggle after which saved within the Hugging Face Datasets Hub for streamlined entry and integration. The first datasets used embody:
- Animes: A dataset detailing anime titles and related metadata.
- Anime_UserRatings: Consumer ranking knowledge for every anime.
- UserRatings: Common consumer scores offering insights into viewing habits.
Pre-requisites for Anime Advice App
Earlier than we start, guarantee that you’ve got accomplished the next steps:
1. Signal Up and Log In
- Go to Hugging Face and create an account for those who haven’t already.
- Log in to your Hugging Face account to entry the Areas part.
2. Create a New Area
- Navigate to the “Areas” part out of your profile or dashboard.
- Click on on the “Create New Area” button.
- Present a singular title in your area and select the “Streamlit” possibility for the app interface.
- Set your area to public or personal primarily based in your choice.
3. Clone the Area Repository
- After creating the Area, you’ll be redirected to the repository web page in your new area.
- Clone the repository to your native machine utilizing Git with the next command:
git clone https://huggingface.co/areas/your-username/your-space-name4. Set Up the Digital Surroundings
- Navigate to your undertaking listing and create a brand new digital setting utilizing Python’s built-in venv device.
# Creating the Digital setting
## For macOS and Linux:
python3 -m venv env
## For Home windows:
python -m venv env
# Activation the setting
## For macOS and Linux:
supply env/bin/activate
## For Home windows:
.envScriptsactivate5. Set up Dependencies
- Within the cloned repository, create a necessities.txt file that lists all of the dependencies your app requires (e.g., Streamlit, pandas, and so on.).
- Set up the dependencies utilizing the command:
pip set up -r necessities.txtEarlier than diving into the code, it’s important to grasp how the varied elements of the system work together. Try the beneath undertaking structure.
Folder Construction
This undertaking adopts a modular folder construction designed to align with business requirements, making certain scalability and maintainability.
ANIME-RECOMMENDATION-SYSTEM/ # Undertaking listing
├── anime_recommender/ # Primary package deal containing all of the modules
│ │── __init__.py # Package deal initialization
│ │
│ ├── elements/ # Core elements of the advice system
│ │ │── __init__.py # Package deal initialization
│ │ │── collaborative_recommender.py # Collaborative filtering mannequin
│ │ │── content_based_recommender.py # Content material-based filtering mannequin
│ │ │── data_ingestion.py # Fetches and masses knowledge
│ │ │── data_transformation.py # Preprocesses and transforms the information
│ │ │── top_anime_recommenders.py # Filters prime animes
│ │
│ ├── fixed/
│ │ │── __init__.py # Shops fixed values used throughout the undertaking
│ │
│ ├── entity/ # Defines structured entities like configs and artifacts
│ │ │── __init__.py
│ │ │── artifact_entity.py # Information constructions for mannequin artifacts
│ │ │── config_entity.py # Configuration parameters and settings
│ │
│ ├── exception/ # Customized exception dealing with
│ │ │── __init__.py
│ │ │── exception.py # Handles errors and exceptions
│ │
│ ├── loggers/ # Logging and monitoring setup
│ │ │── __init__.py
│ │ │── logging.py # Configures log settings
│ │
│ ├── model_trainer/ # Mannequin coaching scripts
│ │ │── __init__.py
│ │ │── collaborative_modelling.py # Practice collaborative filtering mannequin
│ │ │── content_based_modelling.py # Practice content-based mannequin
│ │ │── top_anime_filtering.py # Filters prime animes primarily based on scores
│ │
│ ├── pipelines/ # Finish-to-end ML pipelines
│ │ │── __init__.py
│ │ │── training_pipeline.py # Coaching pipeline
│ │
│ ├── utils/ # Utility features
│ │ │── __init__.py
│ │ ├── main_utils/
│ │ │ │── __init__.py
│ │ │ │── utils.py # Utility features for particular processing
├── notebooks/ # Jupyter notebooks for EDA and experimentation
│ ├── EDA.ipynb # Exploratory Information Evaluation
│ ├── final_ARS.ipynb # Ultimate implementation pocket book
├── .gitattributes # Git configuration for dealing with file codecs
├── .gitignore # Specifies recordsdata to disregard in model management
├── app.py # Primary Streamlit app
├── Dockerfile # Docker configuration for containerization
├── README.md # Undertaking documentation
├── necessities.txt # Dependencies and libraries
├── run_pipeline.py # Runs the whole coaching pipeline
├── setup.py # Setup script for package deal set upConstants
The fixed/__init__.py file defines all important constants, resembling file paths, listing names, and mannequin filenames. These constants standardize configurations throughout the information ingestion, transformation, and mannequin coaching phases. This ensures consistency, maintainability, and quick access to key undertaking configurations.
"""Defining frequent fixed variables for coaching pipeline"""
PIPELINE_NAME: str = "AnimeRecommender"
ARTIFACT_DIR: str = "Artifacts"
ANIME_FILE_NAME: str = "Animes.csv"
RATING_FILE_NAME:str = "UserRatings.csv"
MERGED_FILE_NAME:str = "Anime_UserRatings.csv"
ANIME_FILE_PATH:str = "krishnaveni76/Animes"
RATING_FILE_PATH:str = "krishnaveni76/UserRatings"
ANIMEUSERRATINGS_FILE_PATH:str = "krishnaveni76/Anime_UserRatings"
MODELS_FILEPATH = "krishnaveni76/anime-recommendation-models"
"""Information Ingestion associated fixed begin with DATA_INGESTION VAR NAME"""
DATA_INGESTION_DIR_NAME: str = "data_ingestion"
DATA_INGESTION_FEATURE_STORE_DIR: str = "feature_store"
DATA_INGESTION_INGESTED_DIR: str = "ingested"
"""Information Transformation associated fixed begin with DATA_VALIDATION VAR NAME"""
DATA_TRANSFORMATION_DIR:str = "data_transformation"
DATA_TRANSFORMATION_TRANSFORMED_DATA_DIR:str = "remodeled"
"""Mannequin Coach associated fixed begin with MODEL TRAINER VAR NAME"""
MODEL_TRAINER_DIR_NAME: str = "trained_models"
MODEL_TRAINER_COL_TRAINED_MODEL_DIR: str = "collaborative_recommenders"
MODEL_TRAINER_SVD_TRAINED_MODEL_NAME: str = "svd.pkl"
MODEL_TRAINER_ITEM_KNN_TRAINED_MODEL_NAME: str = "itembasedknn.pkl"
MODEL_TRAINER_USER_KNN_TRAINED_MODEL_NAME: str = "userbasedknn.pkl"
MODEL_TRAINER_CON_TRAINED_MODEL_DIR:str = "content_based_recommenders"
MODEL_TRAINER_COSINESIMILARITY_MODEL_NAME:str = "cosine_similarity.pkl"Utils
The utils/main_utils/utils.py file incorporates utility features for operations resembling saving/loading knowledge, exporting dataframes, saving fashions, and importing fashions to Hugging Face. These reusable features streamline processes all through the undertaking.
def export_data_to_dataframe(dataframe: pd.DataFrame, file_path: str) -> pd.DataFrame:
dir_path = os.path.dirname(file_path)
os.makedirs(dir_path, exist_ok=True)
dataframe.to_csv(file_path, index=False, header=True)
return dataframe
def load_csv_data(file_path: str) -> pd.DataFrame:
df = pd.read_csv(file_path)
return df
def save_model(mannequin: object, file_path: str) -> None:
os.makedirs(os.path.dirname(file_path), exist_ok=True)
with open(file_path, "wb") as file_obj:
joblib.dump(mannequin, file_obj)
def load_object(file_path: str) -> object:
if not os.path.exists(file_path):
error_msg = f"The file: {file_path} doesn't exist."
elevate Exception(error_msg)
with open(file_path, "rb") as file_obj:
return joblib.load(file_obj)
def upload_model_to_huggingface(model_path: str, repo_id: str, filename: str):
api = HfApi()
api.upload_file(path_or_fileobj=model_path,path_in_repo=filename,=repo_id,repo_type="mannequin" ) Configuration Setup
The entity/config_entity.py file holds configuration particulars for various phases of the coaching pipeline. This consists of paths for knowledge ingestion, transformation, and mannequin coaching for each collaborative and content-based advice techniques. These configurations guarantee a structured and arranged workflow all through the undertaking.
class TrainingPipelineConfig:
def __init__(self, timestamp=datetime.now()):
timestamp = timestamp.strftime("%m_percentd_percentY_percentH_percentM_percentS")
self.pipeline_name = PIPELINE_NAME
self.artifact_dir = os.path.be a part of(ARTIFACT_DIR, timestamp)
self.model_dir=os.path.be a part of("final_model")
self.timestamp: str = timestamp
class DataIngestionConfig:
def __init__(self, training_pipeline_config: TrainingPipelineConfig):
self.data_ingestion_dir: str = os.path.be a part of(training_pipeline_config.artifact_dir, DATA_INGESTION_DIR_NAME)
self.feature_store_anime_file_path: str = os.path.be a part of(self.data_ingestion_dir, DATA_INGESTION_FEATURE_STORE_DIR, ANIME_FILE_NAME)
self.feature_store_userrating_file_path: str = os.path.be a part of(self.data_ingestion_dir, DATA_INGESTION_FEATURE_STORE_DIR, RATING_FILE_NAME)
self.anime_filepath: str = ANIME_FILE_PATH
self.rating_filepath: str = RATING_FILE_PATH
class DataTransformationConfig:
def __init__(self,training_pipeline_config:TrainingPipelineConfig):
self.data_transformation_dir:str = os.path.be a part of(training_pipeline_config.artifact_dir,DATA_TRANSFORMATION_DIR)
self.merged_file_path:str = os.path.be a part of(self.data_transformation_dir,DATA_TRANSFORMATION_TRANSFORMED_DATA_DIR,MERGED_FILE_NAME)
class CollaborativeModelConfig:
def __init__(self,training_pipeline_config:TrainingPipelineConfig):
self.model_trainer_dir:str = os.path.be a part of(training_pipeline_config.artifact_dir,MODEL_TRAINER_DIR_NAME)
self.svd_trained_model_file_path:str = os.path.be a part of(self.model_trainer_dir,MODEL_TRAINER_COL_TRAINED_MODEL_DIR,MODEL_TRAINER_SVD_TRAINED_MODEL_NAME)
self.user_knn_trained_model_file_path:str = os.path.be a part of(self.model_trainer_dir,MODEL_TRAINER_COL_TRAINED_MODEL_DIR,MODEL_TRAINER_USER_KNN_TRAINED_MODEL_NAME)
self.item_knn_trained_model_file_path:str = os.path.be a part of(self.model_trainer_dir,MODEL_TRAINER_COL_TRAINED_MODEL_DIR,MODEL_TRAINER_ITEM_KNN_TRAINED_MODEL_NAME)
class ContentBasedModelConfig:
def __init__(self,training_pipeline_config:TrainingPipelineConfig):
self.model_trainer_dir:str = os.path.be a part of(training_pipeline_config.artifact_dir,MODEL_TRAINER_DIR_NAME)
self.cosine_similarity_model_file_path:str = os.path.be a part of(self.model_trainer_dir,MODEL_TRAINER_CON_TRAINED_MODEL_DIR,MODEL_TRAINER_COSINESIMILARITY_MODEL_NAME)Artifacts entity
The entity/artifact_entity.py file defines courses for artifacts generated at varied phases. These artifacts assist monitor and handle intermediate outputs resembling processed datasets and educated fashions.
@dataclass
class DataIngestionArtifact:
feature_store_anime_file_path:str
feature_store_userrating_file_path:str
@dataclass
class DataTransformationArtifact:
merged_file_path:str
@dataclass
class CollaborativeModelArtifact:
svd_file_path:str
item_based_knn_file_path:str
user_based_knn_file_path:str
@dataclass
class ContentBasedModelArtifact:
cosine_similarity_model_file_path:strAdvice System – Mannequin Coaching
On this undertaking, we implement three sorts of advice techniques to boost the anime advice expertise:
- Collaborative Advice System
- Content material-Based mostly Advice System
- High Anime Advice System
Every method performs a singular function in delivering personalised suggestions. By breaking down every part, we are going to achieve a deeper understanding.
1. Collaborative Advice System
This Collaborative Advice System suggests gadgets to customers primarily based on the preferences and behaviours of different customers. It operates beneath the belief that if two customers have proven comparable pursuits prior to now, they’re more likely to have comparable preferences sooner or later. This method is extensively utilized in platforms like Netflix, Amazon, and anime advice engines to offer personalised options. In our case, we apply this advice approach to determine customers with comparable preferences and counsel anime primarily based on their shared pursuits.
We are going to observe the beneath workflow to construct our advice system. Every step is fastidiously structured to make sure seamless integration, beginning with knowledge assortment, adopted by transformation, and eventually coaching a mannequin to generate significant suggestions.
A. Information Ingestion
Information ingestion is the method of gathering, importing, and transferring knowledge from varied sources into an information storage system or pipeline for additional processing and evaluation. It’s a essential first step in any data-driven software, because it permits the system to entry and work with the uncooked knowledge required to generate insights, practice fashions, or carry out different duties.
Information Ingestion Part
We outline a DataIngestion class in elements/data_ingestion.py file which handles the method of fetching datasets from Hugging Face Datasets Hub, and loading them into Pandas DataFrames. It makes use of DataIngestionConfig to acquire the required file paths and configurations for the ingestion course of. The ingest_data methodology masses the anime and consumer ranking datasets, exports them as CSV recordsdata to the function retailer, and returns a DataIngestionArtifact containing the paths of the ingested recordsdata. This class encapsulates the information ingestion logic, making certain that knowledge is correctly fetched, saved, and made accessible for additional phases of the pipeline.
class DataIngestion:
def __init__(self, data_ingestion_config: DataIngestionConfig):
self.data_ingestion_config = data_ingestion_config
def fetch_data_from_huggingface(self, dataset_path: str, break up: str = None) -> pd.DataFrame:
dataset = load_dataset(dataset_path, break up=break up)
df = pd.DataFrame(dataset['train'])
return df
def ingest_data(self) -> DataIngestionArtifact:
anime_df = self.fetch_data_from_huggingface(self.data_ingestion_config.anime_filepath)
rating_df = self.fetch_data_from_huggingface(self.data_ingestion_config.rating_filepath)
export_data_to_dataframe(anime_df, file_path=self.data_ingestion_config.feature_store_anime_file_path)
export_data_to_dataframe(rating_df, file_path=self.data_ingestion_config.feature_store_userrating_file_path)
dataingestionartifact = DataIngestionArtifact(
feature_store_anime_file_path=self.data_ingestion_config.feature_store_anime_file_path,
feature_store_userrating_file_path=self.data_ingestion_config.feature_store_userrating_file_path
)
return dataingestionartifact B. Information Transformation
Information transformation is the method of changing uncooked knowledge right into a format or construction that’s appropriate for evaluation, modelling, or integration right into a system. It’s a essential step within the knowledge preprocessing pipeline, particularly for machine studying, because it helps be sure that the information is clear, constant, and formatted in a means that fashions can successfully use.
Information Transformation Part
In elements/data_transformation.py file, we implement the DataTransformation class to handle the transformation of uncooked knowledge right into a cleaned and merged dataset, prepared for additional processing. The category consists of strategies to learn knowledge from CSV recordsdata, merge two datasets (anime and scores), clear and filter the merged knowledge. Particularly, the merge_data methodology combines the datasets primarily based on a standard column (anime_id), whereas the clean_filter_data methodology handles duties like changing lacking values, changing columns to numeric varieties, filtering rows primarily based on circumstances, and eradicating pointless columns. The initiate_data_transformation methodology coordinates the whole transformation course of, storing the ensuing remodeled dataset within the specified location utilizing DataTransformationArtifact entity.
class DataTransformation:
def __init__(self,data_ingestion_artifact:DataIngestionArtifact,data_transformation_config:DataTransformationConfig):
self.data_ingestion_artifact = data_ingestion_artifact
self.data_transformation_config = data_transformation_config
@staticmethod
def read_data(file_path)->pd.DataFrame:
return pd.read_csv(file_path)
@staticmethod
def merge_data(anime_df: pd.DataFrame, rating_df: pd.DataFrame) -> pd.DataFrame:
merged_df = pd.merge(rating_df, anime_df, on="anime_id", how="inside")
return merged_df
@staticmethod
def clean_filter_data(merged_df: pd.DataFrame) -> pd.DataFrame:
merged_df['average_rating'].substitute('UNKNOWN', np.nan)
merged_df['average_rating'] = pd.to_numeric(merged_df['average_rating'], errors="coerce")
merged_df['average_rating'].fillna(merged_df['average_rating'].median())
merged_df = merged_df[merged_df['average_rating'] > 6]
cols_to_drop = [ 'username', 'overview', 'type', 'episodes', 'producers', 'licensors', 'studios', 'source', 'rank', 'popularity', 'favorites', 'scored by', 'members' ]
cleaned_df = merged_df.copy()
cleaned_df.drop(columns=cols_to_drop, inplace=True)
return cleaned_df
def initiate_data_transformation(self)->DataTransformationArtifact:
anime_df = DataTransformation.read_data(self.data_ingestion_artifact.feature_store_anime_file_path)
rating_df = DataTransformation.read_data(self.data_ingestion_artifact.feature_store_userrating_file_path)
merged_df = DataTransformation.merge_data(anime_df, rating_df)
transformed_df = DataTransformation.clean_filter_data(merged_df)
export_data_to_dataframe(transformed_df, self.data_transformation_config.merged_file_path)
data_transformation_artifact = DataTransformationArtifact( merged_file_path=self.data_transformation_config.merged_file_path)
return data_transformation_artifact C. Collaborative Recommender
The Collaborative filtering is extensively utilized in advice techniques, the place predictions are made primarily based on user-item interactions moderately than specific options of the gadgets.
Collaborative Modelling
The CollaborativeAnimeRecommender class is designed to offer personalised anime suggestions utilizing collaborative filtering strategies. It employs three totally different fashions:
- Singular Worth Decomposition (SVD) :– A matrix factorization approach that learns latent components representing consumer preferences and anime traits, enabling personalised suggestions primarily based on previous scores.
- Merchandise-Based mostly Okay-Nearest Neighbors (KNN) :– Finds comparable anime titles primarily based on consumer ranking patterns, recommending exhibits just like a given anime.
- Consumer-Based mostly Okay-Nearest Neighbors (KNN) :– Identifies customers with comparable preferences and suggests anime that like-minded customers have loved.
The category processes uncooked consumer scores, constructs interplay matrices, and trains the fashions to generate tailor-made suggestions. The recommender supplies predictions for particular person customers, recommends comparable anime titles, and suggests new exhibits primarily based on consumer similarity. By leveraging collaborative filtering strategies, this method enhances consumer expertise by providing personalised and related anime suggestions.
class CollaborativeAnimeRecommender:
def __init__(self, df):
self.df = df
self.svd = None
self.knn_item_based = None
self.knn_user_based = None
self.prepare_data()
def prepare_data(self):
self.df = self.df.drop_duplicates()
reader = Reader(rating_scale=(1, 10))
self.knowledge = Dataset.load_from_df(self.df[['user_id', 'anime_id', 'rating']], reader)
self.anime_pivot = self.df.pivot_table(index='title', columns="user_id", values="ranking").fillna(0)
self.user_pivot = self.df.pivot_table(index='user_id', columns="title", values="ranking").fillna(0)
def train_svd(self):
self.svd = SVD()
cross_validate(self.svd, self.knowledge, cv=5)
trainset = self.knowledge.build_full_trainset()
self.svd.match(trainset)
def train_knn_item_based(self):
item_user_matrix = csr_matrix(self.anime_pivot.values)
self.knn_item_based = NearestNeighbors(metric="cosine", algorithm='brute')
self.knn_item_based.match(item_user_matrix)
def train_knn_user_based(self):
user_item_matrix = csr_matrix(self.user_pivot.values)
self.knn_user_based = NearestNeighbors(metric="cosine", algorithm='brute')
self.knn_user_based.match(user_item_matrix)
def print_unique_user_ids(self):
unique_user_ids = self.df['user_id'].distinctive()
return unique_user_ids
def get_svd_recommendations(self, user_id, n=10, svd_model=None)-> pd.DataFrame:
svd_model = svd_model or self.svd
if svd_model is None:
elevate ValueError("SVD mannequin will not be supplied or educated.")
if user_id not in self.df['user_id'].distinctive():
return f"Consumer ID '' not discovered within the dataset."
anime_ids = self.df['anime_id'].distinctive()
predictions = [(anime_id, svd_model.predict(user_id, anime_id).est) for anime_id in anime_ids]
predictions.type(key=lambda x: x[1], reverse=True)
recommended_anime_ids = [pred[0] for pred in predictions[:n]]
recommended_anime = self.df[self.df['anime_id'].isin(recommended_anime_ids)].drop_duplicates(subset="anime_id")
recommended_anime = recommended_anime.head(n)
return pd.DataFrame({ 'Anime Identify': recommended_anime['name'].values, 'Genres': recommended_anime['genres'].values, 'Picture URL': recommended_anime['image url'].values, 'Ranking': recommended_anime['average_rating'].values})
def get_item_based_recommendations(self, anime_name, n_recommendations=10, knn_item_model=None):
knn_item_based = knn_item_model or self.knn_item_based
if knn_item_based is None:
elevate ValueError("Merchandise-based KNN mannequin will not be supplied or educated.")
if anime_name not in self.anime_pivot.index:
return f"Anime title '{anime_name}' not discovered within the dataset."
query_index = self.anime_pivot.index.get_loc(anime_name)
distances, indices = knn_item_based.kneighbors( self.anime_pivot.iloc[query_index, :].values.reshape(1, -1), n_neighbors=n_recommendations + 1 )
suggestions = []
for i in vary(1, len(distances.flatten())):
anime_title = self.anime_pivot.index[indices.flatten()[i]]
distance = distances.flatten()[i]
suggestions.append((anime_title, distance))
recommended_anime_titles = [rec[0] for rec in suggestions]
filtered_df = self.df[self.df['name'].isin(recommended_anime_titles)].drop_duplicates(subset="title")
filtered_df = filtered_df.head(n_recommendations)
return pd.DataFrame({ 'Anime Identify': filtered_df['name'].values, 'Picture URL': filtered_df['image url'].values, 'Genres': filtered_df['genres'].values, 'Ranking': filtered_df['average_rating'].values })
def get_user_based_recommendations(self, user_id, n_recommendations=10, knn_user_model=None)-> pd.DataFrame:
knn_user_based = knn_user_model or self.knn_user_based
if knn_user_based is None:
elevate ValueError("Consumer-based KNN mannequin will not be supplied or educated.")
user_id = float(user_id)
if user_id not in self.user_pivot.index:
return f"Consumer ID '' not discovered within the dataset."
user_idx = self.user_pivot.index.get_loc(user_id)
distances, indices = knn_user_based.kneighbors( self.user_pivot.iloc[user_idx, :].values.reshape(1, -1), n_neighbors=n_recommendations + 1 )
user_rated_anime = set(self.user_pivot.columns[self.user_pivot.iloc[user_idx, :] > 0])
all_neighbor_ratings = []
for i in vary(1, len(distances.flatten())):
neighbor_idx = indices.flatten()[i]
neighbor_rated_anime = self.user_pivot.iloc[neighbor_idx, :]
neighbor_ratings = neighbor_rated_anime[neighbor_rated_anime > 0]
all_neighbor_ratings.prolong(neighbor_ratings.index)
anime_counter = Counter(all_neighbor_ratings)
suggestions = [(anime, count) for anime, count in anime_counter.items() if anime not in user_rated_anime]
suggestions.type(key=lambda x: x[1], reverse=True)
recommended_anime_titles = [rec[0] for rec in suggestions[:n_recommendations]]
filtered_df = self.df[self.df['name'].isin(recommended_anime_titles)].drop_duplicates(subset="title")
filtered_df = filtered_df.head(n_recommendations)
return pd.DataFrame({ 'Anime Identify': filtered_df['name'].values, 'Picture URL': filtered_df['image url'].values, 'Genres': filtered_df['genres'].values, 'Ranking': filtered_df['average_rating'].values }) Collaborative Mannequin Coach Part
The CollaborativeModelTrainer automates the coaching, saving, and deployment of the fashions. It ensures that educated fashions are saved domestically and likewise uploaded to Hugging Face, making them simply accessible for producing suggestions.
class CollaborativeModelTrainer:
def __init__(self, collaborative_model_trainer_config: CollaborativeModelConfig, data_transformation_artifact: DataTransformationArtifact):
self.collaborative_model_trainer_config = collaborative_model_trainer_config
self.data_transformation_artifact = data_transformation_artifact
def initiate_model_trainer(self) -> CollaborativeModelArtifact:
df = load_csv_data(self.data_transformation_artifact.merged_file_path)
recommender = CollaborativeAnimeRecommender(df)
# Practice and save SVD mannequin
recommender.train_svd()
save_model(mannequin=recommender.svd,file_path= self.collaborative_model_trainer_config.svd_trained_model_file_path)
upload_model_to_huggingface(
model_path=self.collaborative_model_trainer_config.svd_trained_model_file_path,
repo_id=MODELS_FILEPATH,
filename=MODEL_TRAINER_SVD_TRAINED_MODEL_NAME
)
svd_model = load_object(self.collaborative_model_trainer_config.svd_trained_model_file_path)
svd_recommendations = recommender.get_svd_recommendations(user_id=436, n=10, svd_model=svd_model)
# Practice and save Merchandise-Based mostly KNN mannequin
recommender.train_knn_item_based()
save_model(mannequin=recommender.knn_item_based, file_path=self.collaborative_model_trainer_config.item_knn_trained_model_file_path)
upload_model_to_huggingface(
model_path=self.collaborative_model_trainer_config.item_knn_trained_model_file_path,
repo_id=MODELS_FILEPATH,
filename=MODEL_TRAINER_ITEM_KNN_TRAINED_MODEL_NAME
)
item_knn_model = load_object(self.collaborative_model_trainer_config.item_knn_trained_model_file_path)
item_based_recommendations = recommender.get_item_based_recommendations(
anime_name="One Piece", n_recommendations=10, knn_item_model=item_knn_model
)
# Practice and save Consumer-Based mostly KNN mannequin
recommender.train_knn_user_based()
save_model(mannequin=recommender.knn_user_based,file_path= self.collaborative_model_trainer_config.user_knn_trained_model_file_path)
upload_model_to_huggingface(
model_path=self.collaborative_model_trainer_config.user_knn_trained_model_file_path,
repo_id=MODELS_FILEPATH,
filename=MODEL_TRAINER_USER_KNN_TRAINED_MODEL_NAME
)
user_knn_model = load_object(self.collaborative_model_trainer_config.user_knn_trained_model_file_path)
user_based_recommendations = recommender.get_user_based_recommendations(
user_id=817, n_recommendations=10, knn_user_model=user_knn_model
)
return CollaborativeModelArtifact(
svd_file_path=self.collaborative_model_trainer_config.svd_trained_model_file_path,
item_based_knn_file_path=self.collaborative_model_trainer_config.item_knn_trained_model_file_path,
user_based_knn_file_path=self.collaborative_model_trainer_config.user_knn_trained_model_file_path
) 2. Content material-Based mostly Advice System
This content-based advice system suggests gadgets to customers by analyzing the attributes of things resembling style, key phrases, or descriptions to generate suggestions primarily based on similarity.
For instance, in an anime advice system, if a consumer enjoys a specific anime, the mannequin identifies comparable anime primarily based on attributes like style, voice actors, or themes. Methods resembling TF-IDF (Time period Frequency-Inverse Doc Frequency), cosine similarity, and machine studying fashions assist in rating and suggesting related gadgets.
In contrast to collaborative filtering, which depends upon consumer interactions, content-based filtering is impartial of different customers’ preferences, making it efficient even in circumstances with fewer consumer interactions (chilly begin drawback).
A. Information Ingestion
We use the artifacts from the information ingestion part mentioned earlier to coach the content-based recommender.
B. Content material-Based mostly Recommender
The Content material-Based mostly recommender is chargeable for coaching advice fashions that analyze merchandise attributes to generate personalised options. It processes knowledge, extracts related options, and builds fashions that determine similarities between gadgets primarily based on their content material.
Content material-Based mostly Modelling
The ContentBasedRecommender class leverages TF-IDF (Time period Frequency-Inverse Doc Frequency) and Cosine Similarity to counsel anime primarily based on their style similarities. The mannequin first processes the dataset by eradicating lacking values and changing textual style info into numerical function vectors utilizing TF-IDF vectorization. It then computes the cosine similarity between anime titles to measure their content material similarity. The educated mannequin is saved and later used to offer personalised suggestions by retrieving essentially the most comparable anime primarily based on a given title.
class ContentBasedRecommender:
def __init__(self, df):
self.df = df.dropna()
self.indices = pd.Sequence(self.df.index, index=self.df['name']).drop_duplicates()
self.tfv = TfidfVectorizer( min_df=3, strip_accents="unicode", analyzer="phrase", token_pattern=r'w{1,}', ngram_range=(1, 3), stop_words="english" )
self.tfv_matrix = self.tfv.fit_transform(self.df['genres'])
self.cosine_sim = cosine_similarity(self.tfv_matrix, self.tfv_matrix)
def save_model(self, model_path):
os.makedirs(os.path.dirname(model_path), exist_ok=True)
with open(model_path, 'wb') as f:
joblib.dump((self.tfv, self.cosine_sim), f)
def get_rec_cosine(self, title, model_path, n_recommendations=5):
with open(model_path, 'rb') as f:
self.tfv, self.cosine_sim = joblib.load(f)
if self.df is None:
elevate ValueError("The DataFrame will not be loaded, can't make suggestions.")
if title not in self.indices.index:
return f"Anime title '{title}' not discovered within the dataset."
idx = self.indicesHow to Construct an Anime Advice System?
cosinesim_scores = record(enumerate(self.cosine_sim[idx]))
cosinesim_scores = sorted(cosinesim_scores, key=lambda x: x[1], reverse=True)[1:n_recommendations + 1]
anime_indices = [i[0] for i in cosinesim_scores]
return pd.DataFrame({ 'Anime title': self.df['name'].iloc[anime_indices].values, 'Picture URL': self.df['image url'].iloc[anime_indices].values, 'Genres': self.df['genres'].iloc[anime_indices].values, 'Ranking': self.df['average_rating'].iloc[anime_indices].values }) Content material-Based mostly Mannequin Coach Part
The ContentBasedModelTrainer class is chargeable for automating the coaching and deployment of a content-based advice mannequin. It masses the processed anime dataset from the information ingestion artifact, initializes the ContentBasedRecommender, and trains it utilizing TF-IDF vectorization and cosine similarity. The educated mannequin is then saved and uploaded to Hugging Face.
class ContentBasedModelTrainer:
def __init__(self, content_based_model_trainer_config: ContentBasedModelConfig, data_ingestion_artifact: DataIngestionArtifact):
self.content_based_model_trainer_config = content_based_model_trainer_config
self.data_ingestion_artifact = data_ingestion_artifact
def initiate_model_trainer(self) -> ContentBasedModelArtifact:
df = load_csv_data(self.data_ingestion_artifact.feature_store_anime_file_path)
recommender = ContentBasedRecommender(df=df )
recommender.save_model(model_path=self.content_based_model_trainer_config.cosine_similarity_model_file_path)
upload_model_to_huggingface(
model_path=self.content_based_model_trainer_config.cosine_similarity_model_file_path,
repo_id=MODELS_FILEPATH,
filename=MODEL_TRAINER_COSINESIMILARITY_MODEL_NAME
)
cosine_recommendations = recommender.get_rec_cosine(title="One Piece", model_path=self.content_based_model_trainer_config.cosine_similarity_model_file_path, n_recommendations=10)
content_model_trainer_artifact = ContentBasedModelArtifact( cosine_similarity_model_file_path=self.content_based_model_trainer_config.cosine_similarity_model_file_path )
return content_model_trainer_artifact3. High Anime Advice System
It is not uncommon for newcomers to anime to hunt out the preferred titles first. This prime anime advice system is designed to assist these new to the anime world simply uncover fashionable, extremely rated, and top-ranked anime multi functional place through the use of easy sorting and filtering.
A. Information Ingestion
We make the most of the artifacts from the beforehand mentioned knowledge ingestion part on this advice system.
B. High Anime Recommender Part
High anime filtering
The PopularityBasedFiltering class is chargeable for rating and sorting anime utilizing predefined popularity-based parameters. It analyzes the dataset by evaluating attributes resembling ranking, variety of favorites, group dimension, and rating place. The category consists of specialised features to extract top-performing anime inside every class, making certain a structured method to filtering. Moreover, it manages lacking knowledge and refines the output for readability. By offering data-driven insights, this class performs an important function in figuring out fashionable and highly-rated anime for advice functions.
class PopularityBasedFiltering:
def __init__(self, df):
self.df = df
self.df['average_rating'] = pd.to_numeric(self.df['average_rating'], errors="coerce")
self.df['average_rating'].fillna(self.df['average_rating'].median())
def popular_animes(self, n=10):
sorted_df = self.df.sort_values(by=['popularity'], ascending=True)
top_n_anime = sorted_df.head(n)
return self._format_output(top_n_anime)
def top_ranked_animes(self, n=10):
self.df['rank'] = self.df['rank'].substitute('UNKNOWN', np.nan).astype(float)
df_filtered = self.df[self.df['rank'] > 1]
sorted_df = df_filtered.sort_values(by=['rank'], ascending=True)
top_n_anime = sorted_df.head(n)
return self._format_output(top_n_anime)
def overall_top_rated_animes(self, n=10):
sorted_df = self.df.sort_values(by=['average_rating'], ascending=False)
top_n_anime = sorted_df.head(n)
return self._format_output(top_n_anime)
def favorite_animes(self, n=10):
sorted_df = self.df.sort_values(by=['favorites'], ascending=False)
top_n_anime = sorted_df.head(n)
return self._format_output(top_n_anime)
def top_animes_members(self, n=10):
sorted_df = self.df.sort_values(by=['members'], ascending=False)
top_n_anime = sorted_df.head(n)
return self._format_output(top_n_anime)
def popular_anime_among_members(self, n=10):
sorted_df = self.df.sort_values(by=['members', 'average_rating'], ascending=[False, False]).drop_duplicates(subset="title")
popular_animes = sorted_df.head(n)
return self._format_output(popular_animes)
def top_avg_rated(self, n=10):
self.df['average_rating'] = pd.to_numeric(self.df['average_rating'], errors="coerce")
median_rating = self.df['average_rating'].median()
self.df['average_rating'].fillna(median_rating)
top_animes = ( self.df.drop_duplicates(subset="title").nlargest(n, 'average_rating')[['name', 'average_rating', 'image url', 'genres']] )
return self._format_output(top_animes)
def _format_output(self, anime_df):
return pd.DataFrame({ 'Anime title': anime_df['name'].values, 'Picture URL': anime_df['image url'].values, 'Genres': anime_df['genres'].values, 'Ranking': anime_df['average_rating'].values })High anime recommenders
The PopularityBasedRecommendor class is chargeable for recommending anime primarily based on totally different reputation metrics. It makes use of an anime dataset saved in feature_store_anime_file_path, which was a DataIngestionArtifact. The category integrates the PopularityBasedFiltering class to generate anime suggestions based on varied filtering standards, resembling top-ranked anime, hottest selections, group favorites, and highest-rated exhibits. By deciding on a particular filter_type, customers can retrieve the most effective match primarily based on their most well-liked standards.
class PopularityBasedRecommendor:
def __init__(self,data_ingestion_artifact = DataIngestionArtifact):
self.data_ingestion_artifact = data_ingestion_artifact
def initiate_model_trainer(self,filter_type:str):
df = load_csv_data(self.data_ingestion_artifact.feature_store_anime_file_path)
recommender = PopularityBasedFiltering(df)
if filter_type == 'popular_animes':
popular_animes = recommender.popular_animes(n =10)
elif filter_type == 'top_ranked_animes':
top_ranked_animes = recommender.top_ranked_animes(n =10)
elif filter_type == 'overall_top_rated_animes':
overall_top_rated_animes = recommender.overall_top_rated_animes(n =10)
elif filter_type == 'favorite_animes':
favorite_animes = recommender.favorite_animes(n =10)
elif filter_type == 'top_animes_members':
top_animes_members = recommender.top_animes_members(n = 10)
elif filter_type == 'popular_anime_among_members':
popular_anime_among_members = recommender.popular_anime_among_members(n =10)
elif filter_type == 'top_avg_rated':
top_avg_rated = recommender.top_avg_rated(n =10) Coaching Pipeline
This Machine Studying Coaching Pipeline is designed to automate and streamline the method of constructing recommender fashions effectively. The pipeline follows a structured workflow, starting with knowledge ingestion from Hugging face, adopted by knowledge transformation to preprocess and put together the information for mannequin coaching. It incorporates totally different modelling strategies, resembling collaborative filtering, content-based approaches and Recognition-based filtering, making certain optimum efficiency. The ultimate educated fashions are saved in a Mannequin Hub, enabling seamless deployment and steady refinement. This structured method ensures scalability, effectivity, and reproducibility in machine studying workflows.
class TrainingPipeline:
def __init__(self):
self.training_pipeline_config = TrainingPipelineConfig()
def start_data_ingestion(self) -> DataIngestionArtifact:
data_ingestion_config = DataIngestionConfig(self.training_pipeline_config)
data_ingestion = DataIngestion(data_ingestion_config=data_ingestion_config)
data_ingestion_artifact = data_ingestion.ingest_data()
return data_ingestion_artifact
def start_data_transformation(self, data_ingestion_artifact: DataIngestionArtifact) -> DataTransformationArtifact:
data_transformation_config = DataTransformationConfig(self.training_pipeline_config)
data_transformation = DataTransformation(
data_ingestion_artifact=data_ingestion_artifact,
data_transformation_config=data_transformation_config
)
data_transformation_artifact = data_transformation.initiate_data_transformation()
return data_transformation_artifact
def start_collaborative_model_training(self, data_transformation_artifact: DataTransformationArtifact) -> CollaborativeModelArtifact:
collaborative_model_config = CollaborativeModelConfig(self.training_pipeline_config)
collaborative_model_trainer = CollaborativeModelTrainer(
collaborative_model_trainer_config=collaborative_model_config,
data_transformation_artifact=data_transformation_artifact )
collaborative_model_trainer_artifact = collaborative_model_trainer.initiate_model_trainer()
return collaborative_model_trainer_artifact
def start_content_based_model_training(self, data_ingestion_artifact: DataIngestionArtifact) -> ContentBasedModelArtifact:
content_based_model_config = ContentBasedModelConfig(self.training_pipeline_config)
content_based_model_trainer = ContentBasedModelTrainer(
content_based_model_trainer_config=content_based_model_config,
data_ingestion_artifact=data_ingestion_artifact )
content_based_model_trainer_artifact = content_based_model_trainer.initiate_model_trainer()
return content_based_model_trainer_artifact
def start_popularity_based_filtering(self, data_ingestion_artifact: DataIngestionArtifact):
filtering = PopularityBasedRecommendor(data_ingestion_artifact=data_ingestion_artifact)
suggestions = filtering.initiate_model_trainer(filter_type="popular_animes")
return suggestions
def run_pipeline(self):
# Information Ingestion
data_ingestion_artifact = self.start_data_ingestion()
# Content material-Based mostly Mannequin Coaching
content_based_model_trainer_artifact = self.start_content_based_model_training(data_ingestion_artifact)
# Recognition-Based mostly Filtering
popularity_recommendations = self.start_popularity_based_filtering(data_ingestion_artifact)
# Information Transformation
data_transformation_artifact = self.start_data_transformation(data_ingestion_artifact)
# Collaborative Mannequin Coaching
collaborative_model_trainer_artifact = self.start_collaborative_model_training(data_transformation_artifact)Now that we’ve accomplished creating the pipeline, run the training_pipeline.py file utilizing the beneath code to view the artifacts generated within the earlier steps.
python training_pipeline.py Streamlit App
The advice software is constructed utilizing Streamlit, a light-weight and interactive framework for creating data-driven net apps. It’s deployed on Hugging Face Areas, permitting customers to discover and work together with the anime advice system seamlessly. This setup supplies an intuitive UI for locating anime suggestions in actual time. Every time you push new adjustments, Hugging Face will redeploy your app mechanically.
Docker Integration for Deployment
The Dockerfile units up a light-weight Python setting utilizing the official Python 3.10 slim-buster picture. It configures the working listing, copies software recordsdata, and installs dependencies from necessities.txt. Lastly, it exposes port 8501 and runs the Streamlit app, making it accessible inside the containerized setting.
# Use the official Python picture as a base
FROM python:3.10-slim-buster
# Set the working listing within the container
WORKDIR /app
# Copy the app recordsdata into the container
COPY . .
# Set up required packages
RUN pip set up -r necessities.txt
# Expose the port that Streamlit makes use of
EXPOSE 8501
# Run the Streamlit app
CMD ["streamlit", "run", "app.py", "--server.port=8501", "--server.address=0.0.0.0"] Key Takeaways
- We’ve got designed an environment friendly, end-to-end pipeline that ensures clean knowledge movement from ingestion to advice, making the system scalable, strong, and production-ready.
- New customers obtain trending anime options by way of a popularity-based engine, whereas returning customers get hyper-personalized picks by way of collaborative filtering fashions.
- By deploying on Hugging Face Areas with mannequin versioning, you obtain cost-free productionization with out paying any AWS/GCP payments whereas sustaining scalability!
- The system leverages Docker for containerization, making certain constant environments throughout totally different deployments.
- Constructed utilizing Streamlit, the app supplies a clear, dynamic, and fascinating consumer expertise, making anime discovery enjoyable and intuitive.
The media proven on this article will not be owned by Analytics Vidhya and is used on the Creator’s discretion.
Conclusion
Congratulations! You will have accomplished constructing the Advice app very quickly. From buying knowledge and preprocessing it to mannequin coaching and deployment, this undertaking highlights the ability of getting issues on the market into the world! However maintain up… we’re not executed but! 💥 There’s an entire lot extra enjoyable to come back! You’re now able to construct on one thing even cooler, like a Film Advice app!
That is just the start of our journey collectively, so buckle up—there are numerous extra thrilling tasks forward! Let’s continue learning and constructing!
Ceaselessly Requested Questions
Ans. Completely! Swap the dataset, modify style weights in constants.py, and voilà – you’ve bought a Squid Sport or Marvel Recommender very quickly!
Ans. Sure! A “Shock Me” button will be simply added utilizing random.alternative(), serving to customers uncover hidden anime gems randomly!
Ans. Their free tier handles ~10K month-to-month visits. In the event you hit Demon Slayer ranges of recognition, improve to PRO ($9/month) for precedence servers.
Good day! I am a passionate AI and Machine Studying fanatic presently exploring the thrilling realms of Deep Studying, MLOps, and Generative AI. I get pleasure from diving into new tasks and uncovering progressive strategies that push the boundaries of expertise. I will be sharing guides, tutorials, and undertaking insights primarily based alone experiences, so we will be taught and develop collectively. Be a part of me on this journey as we discover, experiment, and construct superb options on this planet of AI and past!



{kind=link}