



Introduction
The arrival of enormous language fashions (LLMs) has remodeled synthetic intelligence, enabling organizations to innovate and clear up advanced issues at an unprecedented scale. From powering superior chatbots to enhancing pure language understanding, LLMs have redefined what AI can obtain. Nevertheless, managing the lifecycle of LLMs—from knowledge pre-processing and coaching to deployment and monitoring—presents distinctive challenges. These challenges embody scalability, price administration, safety, and real-time efficiency underneath unpredictable site visitors situations.
1. Kubernetes: A Sport-Changer for LLMOps
Kubernetes, the main container orchestration platform, has emerged because the cornerstone of Giant Language Mannequin Operations (LLMOps), enabling organizations to sort out these challenges effectively. Right here’s an in-depth exploration of how Kubernetes empowers LLMOps with its modular structure, sturdy orchestration capabilities, and a wealthy ecosystem of instruments.
Why Kubernetes Stands Out
Kubernetes is greater than only a container orchestration platform—it’s a sturdy basis for working advanced workflows at scale. Its modular and declarative design makes it an excellent match for LLMOps. Organizations can encapsulate the varied elements of LLM workflows, comparable to knowledge preprocessing pipelines, mannequin servers, and logging methods, into remoted Kubernetes pods. This encapsulation ensures that every element can scale independently, be up to date seamlessly, and carry out optimally with out disrupting different elements of the workflow.
Modularity and Isolation
Encapsulation additionally improves maintainability. For example, a preprocessing pipeline liable for cleansing and tokenizing knowledge can function independently from a mannequin inference pipeline, guaranteeing updates to 1 don’t intrude with the opposite. This modularity turns into significantly crucial in large-scale methods the place frequent modifications and optimizations are the norm.
2. Scalability: Dealing with the Unpredictable
Dynamic Workload Administration
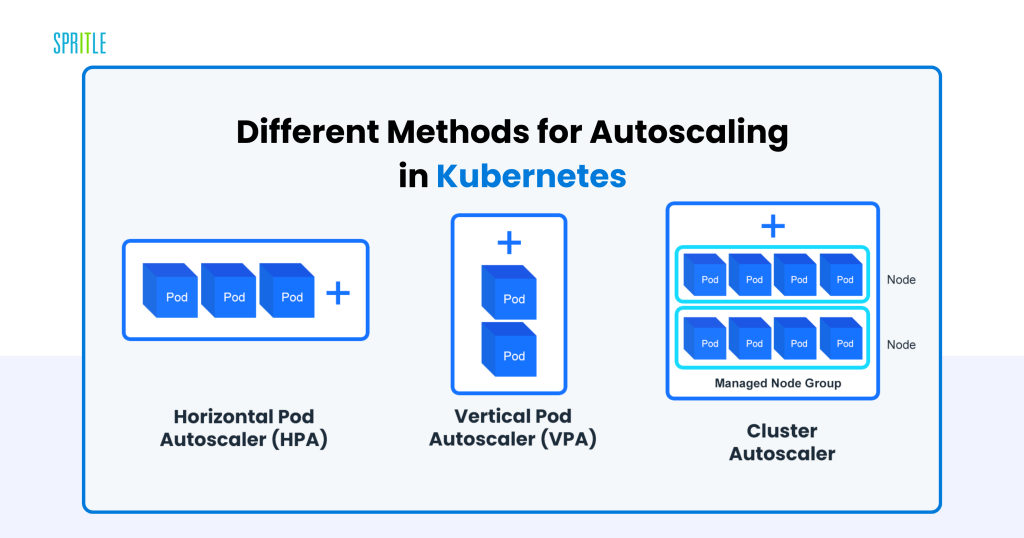
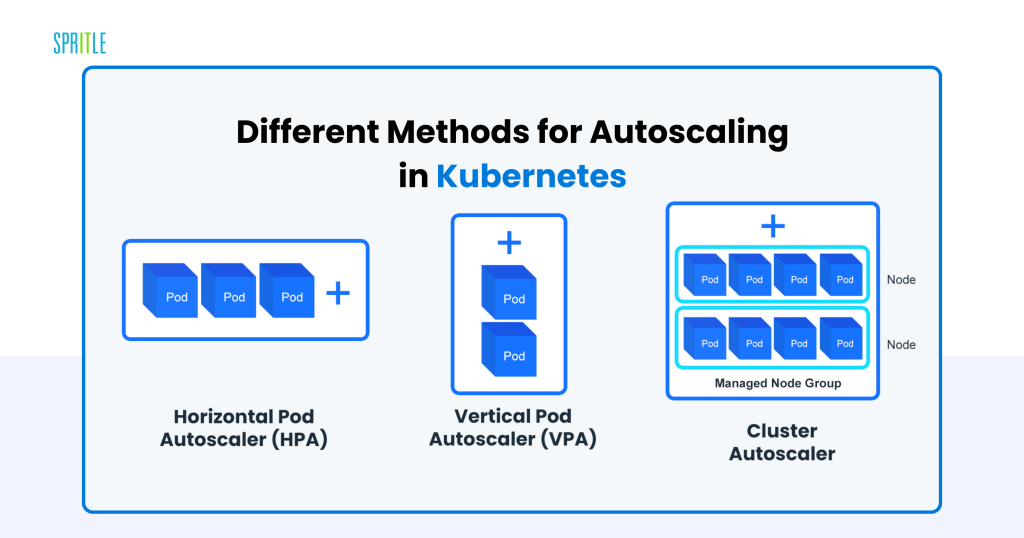
The modularity of Kubernetes is complemented by its unparalleled scalability, making it splendid for LLM workloads characterised by variable site visitors. For example, a surge in person queries to an LLM-powered chatbot can rapidly overwhelm static infrastructure. Kubernetes addresses this by way of:
- Horizontal Pod Autoscaling (HPA): Dynamically adjusts the variety of pods primarily based on metrics like CPU and reminiscence utilization. When demand spikes, HPA spins up extra inference pods to deal with the load.
- Cluster Autoscaler: Mechanically modifies the cluster dimension by including or eradicating nodes to take care of optimum efficiency and cost-efficiency.
Actual-World Instance
Take into account a buyer help chatbot deployed utilizing an LLM. Throughout a product launch, person interactions surge considerably. Kubernetes ensures that the system scales effortlessly to accommodate the elevated site visitors, avoiding downtime or degraded efficiency.
3. Serving Fashions at Scale
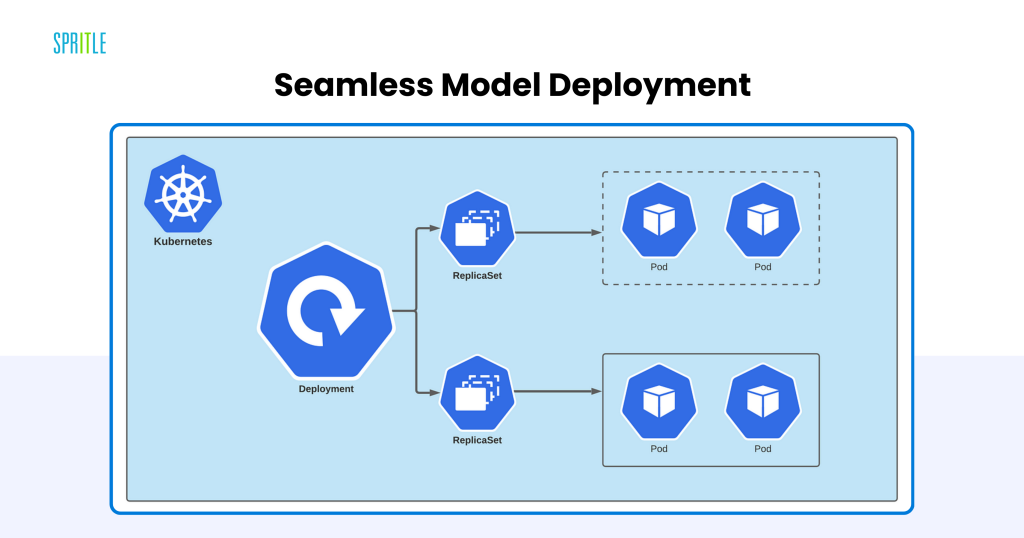
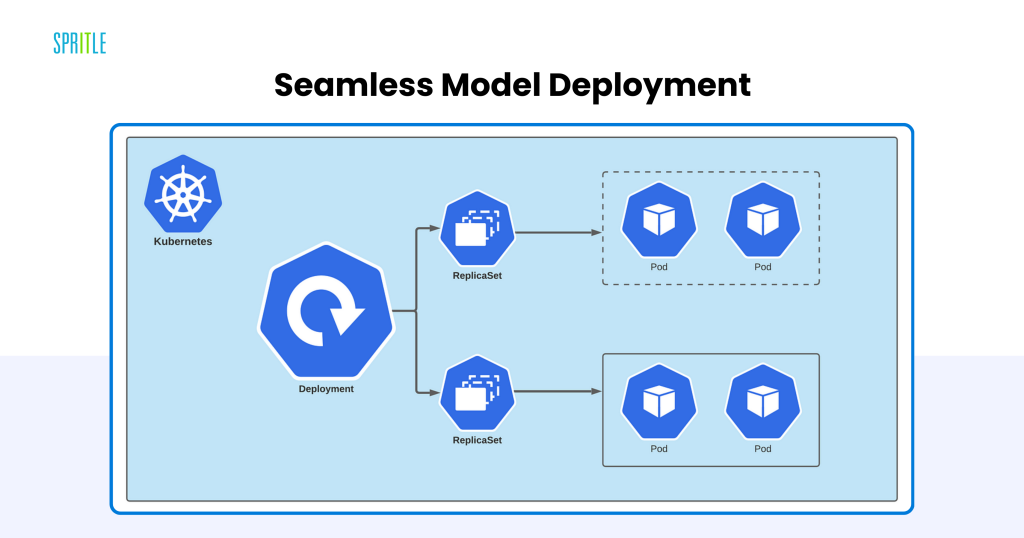
Seamless Mannequin Deployment
Deploying and serving giant language fashions for real-time inference is a crucial problem, and Kubernetes excels on this area. By leveraging instruments like TensorFlow Serving, PyTorch Serve, and FastAPI, builders can expose mannequin endpoints through RESTful APIs or gRPC. These endpoints combine simply with downstream purposes to carry out duties like textual content era, summarization, and classification.
Deployment Methods
Kubernetes helps superior deployment methods comparable to:
- Rolling Updates: Deploy new mannequin variations incrementally, guaranteeing minimal downtime.
- Blue-Inexperienced Deployments: Direct site visitors to a brand new model (blue) whereas preserving the previous model (inexperienced) obtainable as a fallback.
These methods guarantee steady availability, enabling organizations to iterate and enhance their fashions with out disrupting person expertise.
4. Environment friendly Information Preprocessing
Parallel Execution with Jobs and CronJobs
Information preprocessing and have engineering are integral to LLM workflows, involving duties like cleansing, tokenizing, and augmenting datasets. Kubernetes-native instruments deal with these processes effectively:
- Jobs: Allow parallel execution of large-scale preprocessing duties throughout a number of nodes, decreasing processing time.
- CronJobs: Automate recurring duties, comparable to nightly dataset updates or periodic function extraction pipelines.
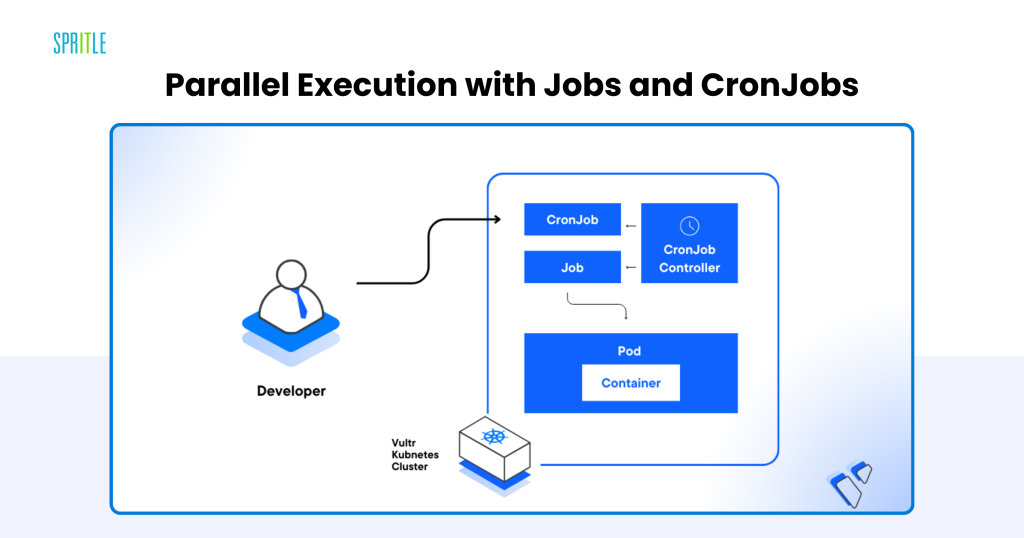
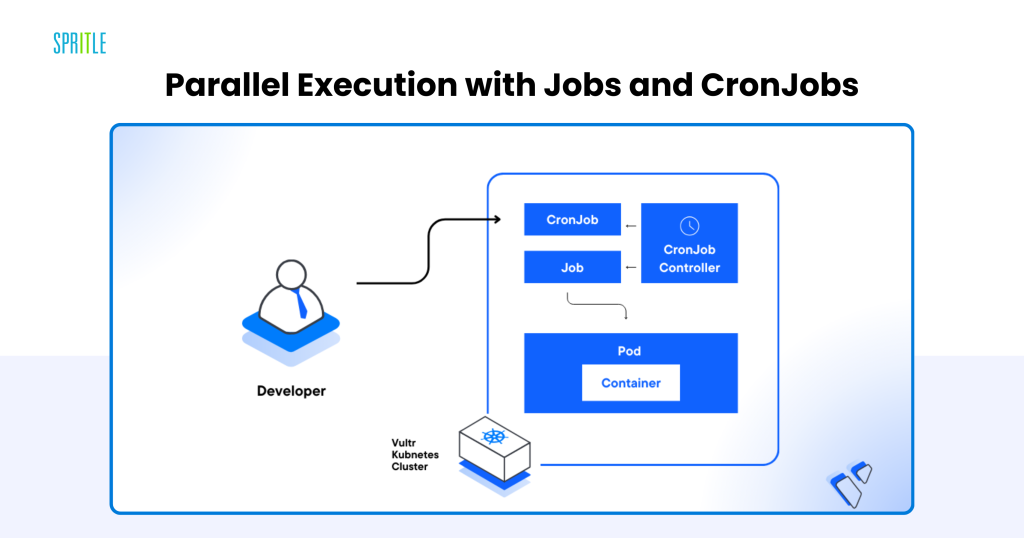
Improved Throughput
The parallelism supplied by Kubernetes ensures that preprocessing doesn’t change into a bottleneck, even for large datasets, making it a precious device for real-time and batch workflows alike.
5. Excessive Availability and Resilience
Guaranteeing Uptime
Excessive availability is a cornerstone of LLMOps, and Kubernetes delivers this with multi-zone and multi-region deployments. By distributing workloads throughout a number of availability zones, Kubernetes ensures that purposes stay operational even within the occasion of localized failures. Multi-region deployments present extra resilience and enhance latency for world customers.
Service Mesh Integration
Service meshes like Istio and Linkerd improve the resilience of Kubernetes deployments by:
- Managing inter-component communication.
- Offering options like load balancing, safe communication, and site visitors shaping.
This ensures sturdy and fault-tolerant communication between elements in advanced LLM workflows.
6. Safety and Compliance
Defending Delicate Information
Safety is paramount in LLMOps, particularly when dealing with delicate knowledge comparable to private or proprietary data. Kubernetes gives a number of built-in options to safe LLM deployments:
- Function-Based mostly Entry Management (RBAC): Enforces fine-grained permissions to restrict entry to crucial sources.
- Community Insurance policies: Limit communication between pods, decreasing the assault floor.
- Secrets and techniques Administration: Securely shops delicate data like API keys and database credentials.
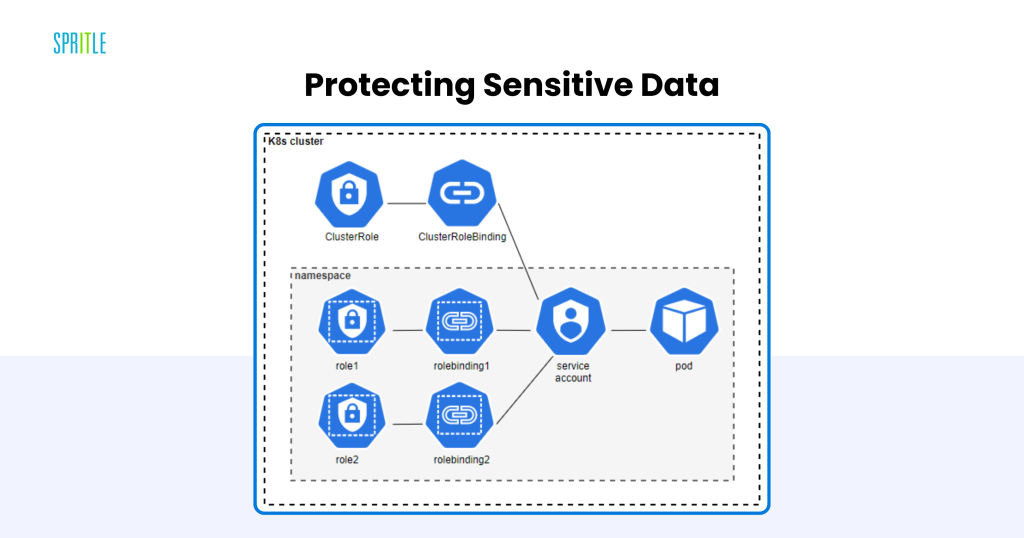
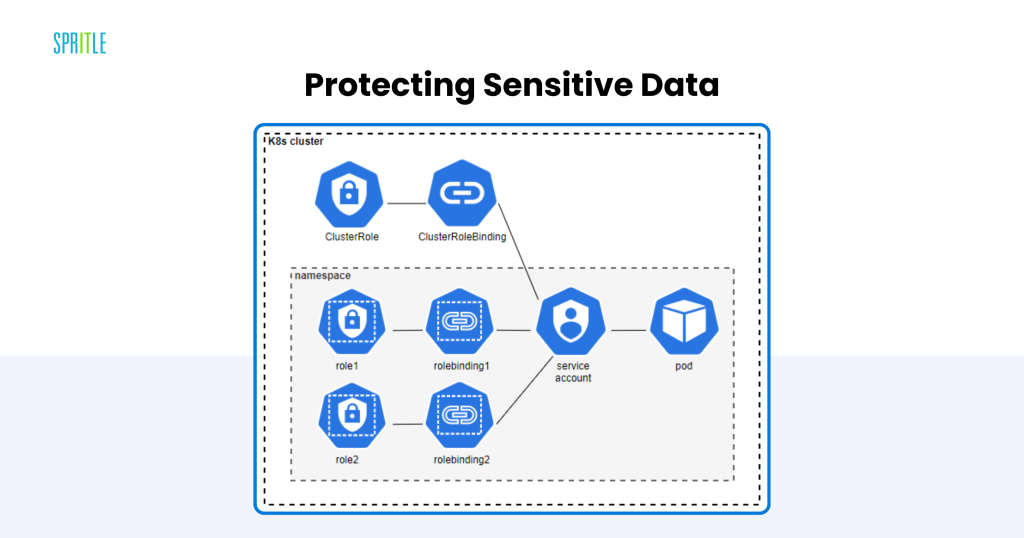
Compliance for Delicate Functions
For industries like healthcare and finance, compliance with rules comparable to GDPR and HIPAA is important. Kubernetes’ sturdy safety features make it simpler to fulfill these necessities, guaranteeing knowledge is dealt with responsibly.
7. Monitoring and Observability
Sustaining System Well being
Monitoring and observability are important for sustaining the efficiency of LLM methods. Kubernetes presents a wealthy ecosystem of instruments for this objective:
- Prometheus and Grafana: Present detailed metrics and visualizations for useful resource utilization, mannequin latency, and error charges.
- Jaeger and OpenTelemetry: Allow distributed tracing, permitting groups to diagnose bottlenecks and latency points throughout workflows.
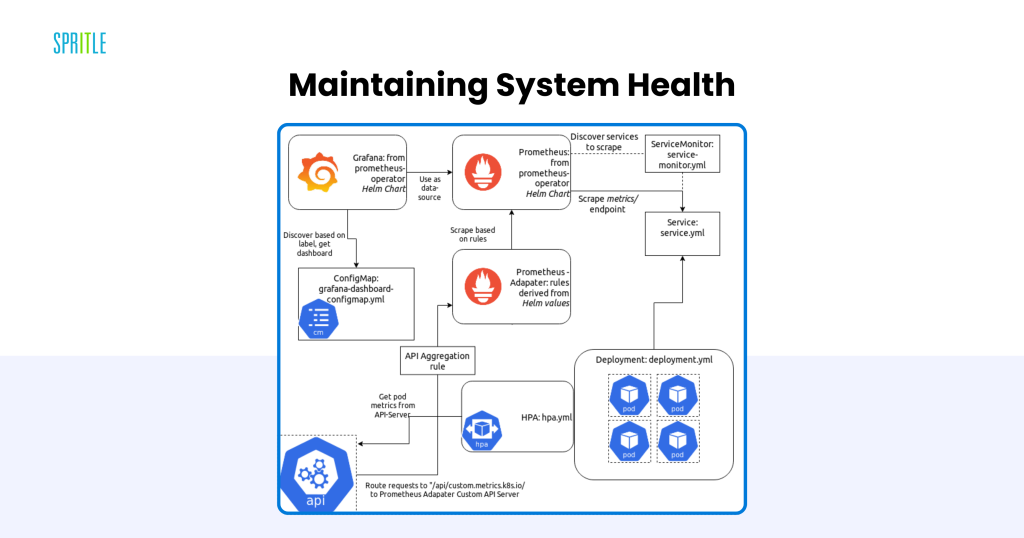
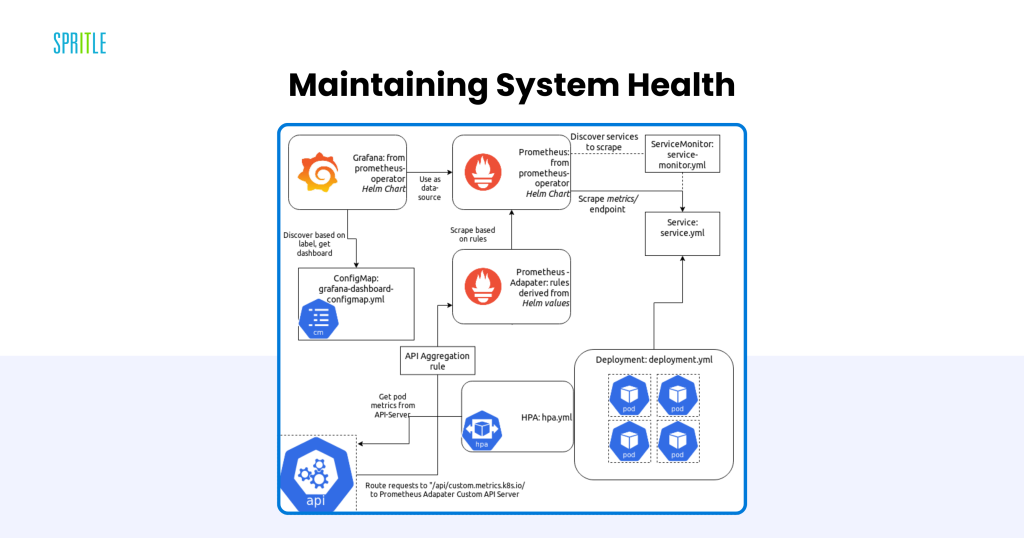
Customized Metrics for LLMs
Inference servers can export customized metrics, comparable to common response time or token era pace, offering insights tailor-made to the particular necessities of LLM-powered purposes.
8. Leveraging Specialised {Hardware}
GPU and TPU Assist
LLMs are computationally intensive, typically requiring GPUs or TPUs for coaching and inference. Kubernetes makes it easy to handle these sources:
- GPU/TPU Scheduling: Ensures environment friendly allocation to pods requiring high-performance computing.
- System Plugins: Expose accelerators to containers, optimizing {hardware} utilization.
Versatile Useful resource Allocation
Organizations can prioritize GPUs for coaching whereas reserving CPUs for lighter inference duties, guaranteeing cost-effective useful resource utilization.
9. Automating ML Pipelines
Streamlined Operations with Kubeflow and Argo
Steady retraining and fine-tuning are important for adapting LLMs to evolving knowledge and necessities. Kubernetes helps this with:
- Kubeflow: Offers an end-to-end ecosystem for machine studying, from knowledge ingestion to serving.
- Argo Workflows: Orchestrates advanced pipelines utilizing Directed Acyclic Graphs (DAGs), simplifying multi-step workflows.
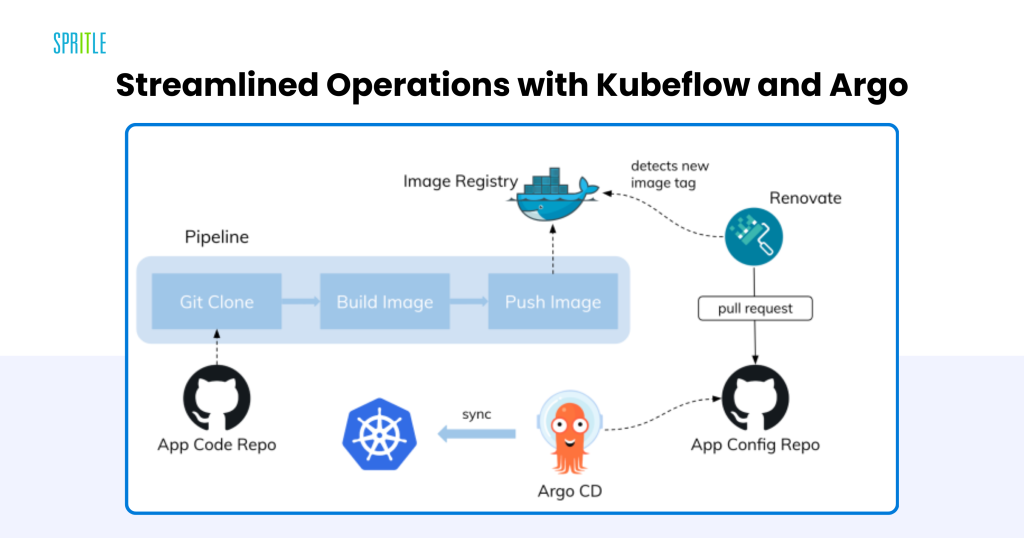
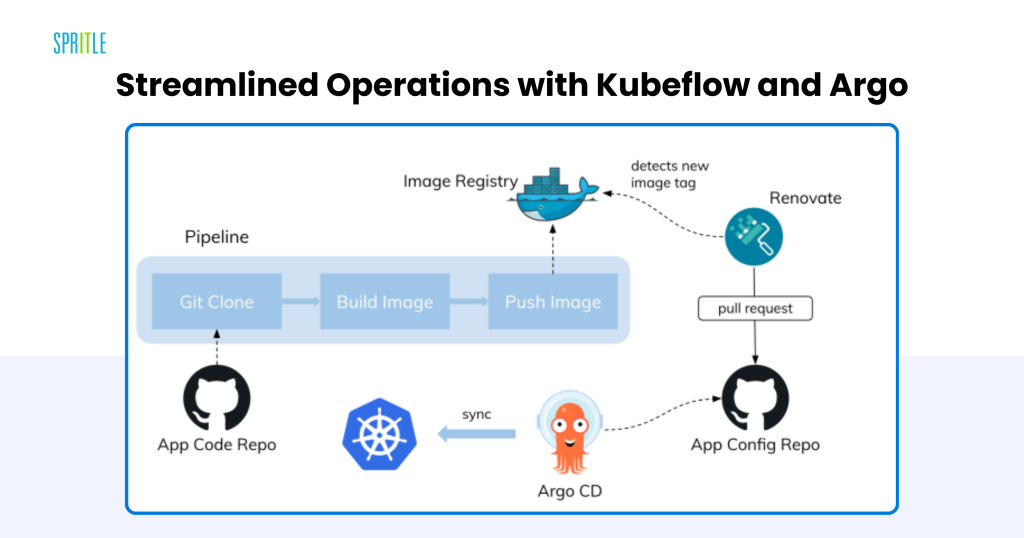
Environment friendly Automation
These instruments cut back guide effort, speed up mannequin iteration, and guarantee workflows are reproducible and dependable.
10. Scalable Storage and Information Administration
Persistent Storage
Kubernetes integrates seamlessly with storage options like Amazon EFS, Google Persistent Disk, and on-premises NFS. This permits large-scale coaching or inference workloads to entry knowledge with out bottlenecks.
Managing Checkpoints and Logs
Kubernetes-native storage integrations simplify the administration of checkpoints and logs, essential for debugging and monitoring mannequin efficiency.
11. Portability Throughout Cloud and On-Premises
Hybrid and Multi-Cloud Methods
Kubernetes gives unmatched portability, permitting LLM workloads to maneuver seamlessly between cloud suppliers or on-premises knowledge facilities. Instruments like Velero and Kasten supply backup and restore capabilities, guaranteeing catastrophe restoration and enterprise continuity.
Federated Kubernetes
Federated clusters allow centralized administration throughout a number of areas, simplifying world deployments and enhancing flexibility.
12. Accelerating Improvement with AI Platforms
Pre-Constructed Integrations
Fashionable AI platforms like Hugging Face Transformers and OpenAI APIs combine seamlessly with Kubernetes, enabling speedy growth and deployment of LLM-powered options.
Instance Use Instances
Utilizing Hugging Face’s Transformers library, organizations can deploy state-of-the-art fashions for duties like sentiment evaluation or summarization with minimal effort.
Conclusion
Kubernetes has redefined the panorama of LLMOps by offering a scalable, resilient, and safe platform for managing giant language fashions. Its modular structure, wealthy orchestration options, and sturdy ecosystem of instruments empower organizations to beat the challenges of LLM deployment at scale. By leveraging Kubernetes, companies can guarantee their AI options stay performant, cost-effective, and adaptable to evolving calls for. As AI continues to advance, Kubernetes stands as a crucial enabler of innovation and operational excellence within the subject of enormous language fashions.

{kind=link}