
Giant language fashions (LLMs) like Claude have modified the best way we use know-how. They energy instruments like chatbots, assist write essays and even create poetry. However regardless of their wonderful talents, these fashions are nonetheless a thriller in some ways. Folks typically name them a “black field” as a result of we will see what they are saying however not how they determine it out. This lack of awareness creates issues, particularly in vital areas like medication or regulation, the place errors or hidden biases may trigger actual hurt.
Understanding how LLMs work is crucial for constructing belief. If we will not clarify why a mannequin gave a selected reply, it is laborious to belief its outcomes, particularly in delicate areas. Interpretability additionally helps establish and repair biases or errors, guaranteeing the fashions are secure and moral. For example, if a mannequin persistently favors sure viewpoints, realizing why may help builders right it. This want for readability is what drives analysis into making these fashions extra clear.
Anthropic, the corporate behind Claude, has been working to open this black field. They’ve made thrilling progress in determining how LLMs suppose, and this text explores their breakthroughs in making Claude’s processes simpler to grasp.
Mapping Claude’s Ideas
In mid-2024, Anthropic’s crew made an thrilling breakthrough. They created a fundamental “map” of how Claude processes info. Utilizing a method referred to as dictionary studying, they discovered hundreds of thousands of patterns in Claude’s “mind”—its neural community. Every sample, or “function,” connects to a selected concept. For instance, some options assist Claude spot cities, well-known folks, or coding errors. Others tie to trickier subjects, like gender bias or secrecy.
Researchers found that these concepts usually are not remoted inside particular person neurons. As a substitute, they’re unfold throughout many neurons of Claude’s community, with every neuron contributing to numerous concepts. That overlap made Anthropic laborious to determine these concepts within the first place. However by recognizing these recurring patterns, Anthropic’s researchers began to decode how Claude organizes its ideas.
Tracing Claude’s Reasoning
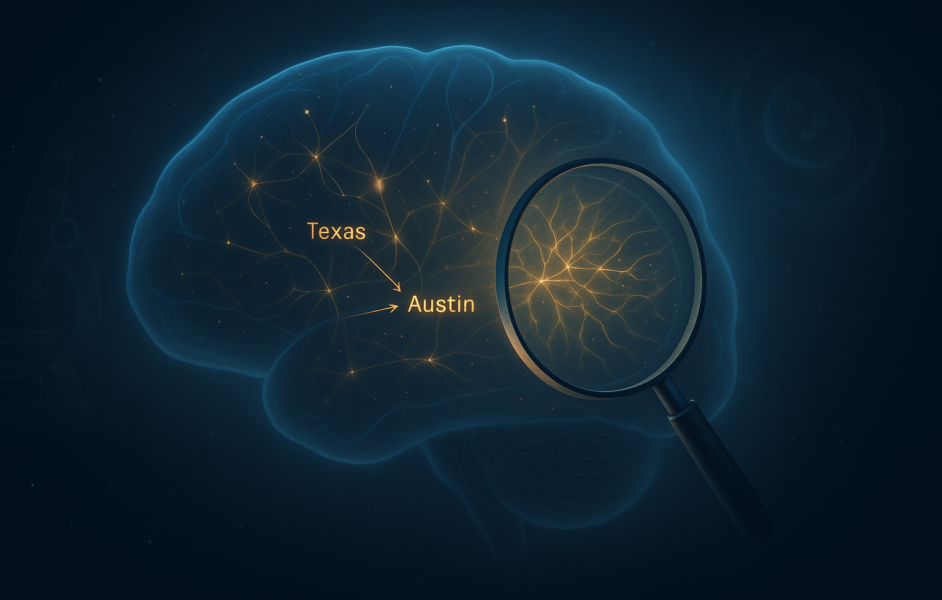
Subsequent, Anthropic needed to see how Claude makes use of these ideas to make choices. They lately constructed a software referred to as attribution graphs, which works like a step-by-step information to Claude’s pondering course of. Every level on the graph is an concept that lights up in Claude’s thoughts, and the arrows present how one concept flows into the subsequent. This graph lets researchers observe how Claude turns a query into a solution.
To raised perceive the working of attribution graphs, take into account this instance: when requested, “What’s the capital of the state with Dallas?” Claude has to appreciate Dallas is in Texas, then recall that Texas’s capital is Austin. The attribution graph confirmed this precise course of—one a part of Claude flagged “Texas,” which led to a different half selecting “Austin.” The crew even examined it by tweaking the “Texas” half, and positive sufficient, it modified the reply. This reveals Claude isn’t simply guessing—it’s working via the issue, and now we will watch it occur.
Why This Issues: An Analogy from Organic Sciences
To see why this issues, it’s handy to consider some main developments in organic sciences. Simply because the invention of the microscope allowed scientists to find cells – the hidden constructing blocks of life – these interpretability instruments are permitting AI researchers to find the constructing blocks of thought inside fashions. And simply as mapping neural circuits within the mind or sequencing the genome paved the best way for breakthroughs in medication, mapping the interior workings of Claude may pave the best way for extra dependable and controllable machine intelligence. These interpretability instruments may play an important function, serving to us to peek into the pondering means of AI fashions.
The Challenges
Even with all this progress, we’re nonetheless removed from totally understanding LLMs like Claude. Proper now, attribution graphs can solely clarify about one in 4 of Claude’s choices. Whereas the map of its options is spectacular, it covers only a portion of what’s happening inside Claude’s mind. With billions of parameters, Claude and different LLMs carry out numerous calculations for each activity. Tracing each to see how a solution varieties is like making an attempt to observe each neuron firing in a human mind throughout a single thought.
There’s additionally the problem of “hallucination.” Generally, AI fashions generate responses that sound believable however are literally false—like confidently stating an incorrect truth. This happens as a result of the fashions depend on patterns from their coaching knowledge somewhat than a real understanding of the world. Understanding why they veer into fabrication stays a troublesome drawback, highlighting gaps in our understanding of their interior workings.
Bias is one other important impediment. AI fashions study from huge datasets scraped from the web, which inherently carry human biases—stereotypes, prejudices, and different societal flaws. If Claude picks up these biases from its coaching, it could replicate them in its solutions. Unpacking the place these biases originate and the way they affect the mannequin’s reasoning is a fancy problem that requires each technical options and cautious consideration of knowledge and ethics.
The Backside Line
Anthropic’s work in making giant language fashions (LLMs) like Claude extra comprehensible is a major step ahead in AI transparency. By revealing how Claude processes info and makes choices, they’re forwarding in direction of addressing key issues about AI accountability. This progress opens the door for secure integration of LLMs into crucial sectors like healthcare and regulation, the place belief and ethics are very important.
As strategies for enhancing interpretability develop, industries which have been cautious about adopting AI can now rethink. Clear fashions like Claude present a transparent path to AI’s future—machines that not solely replicate human intelligence but in addition clarify their reasoning.


{kind=link}