

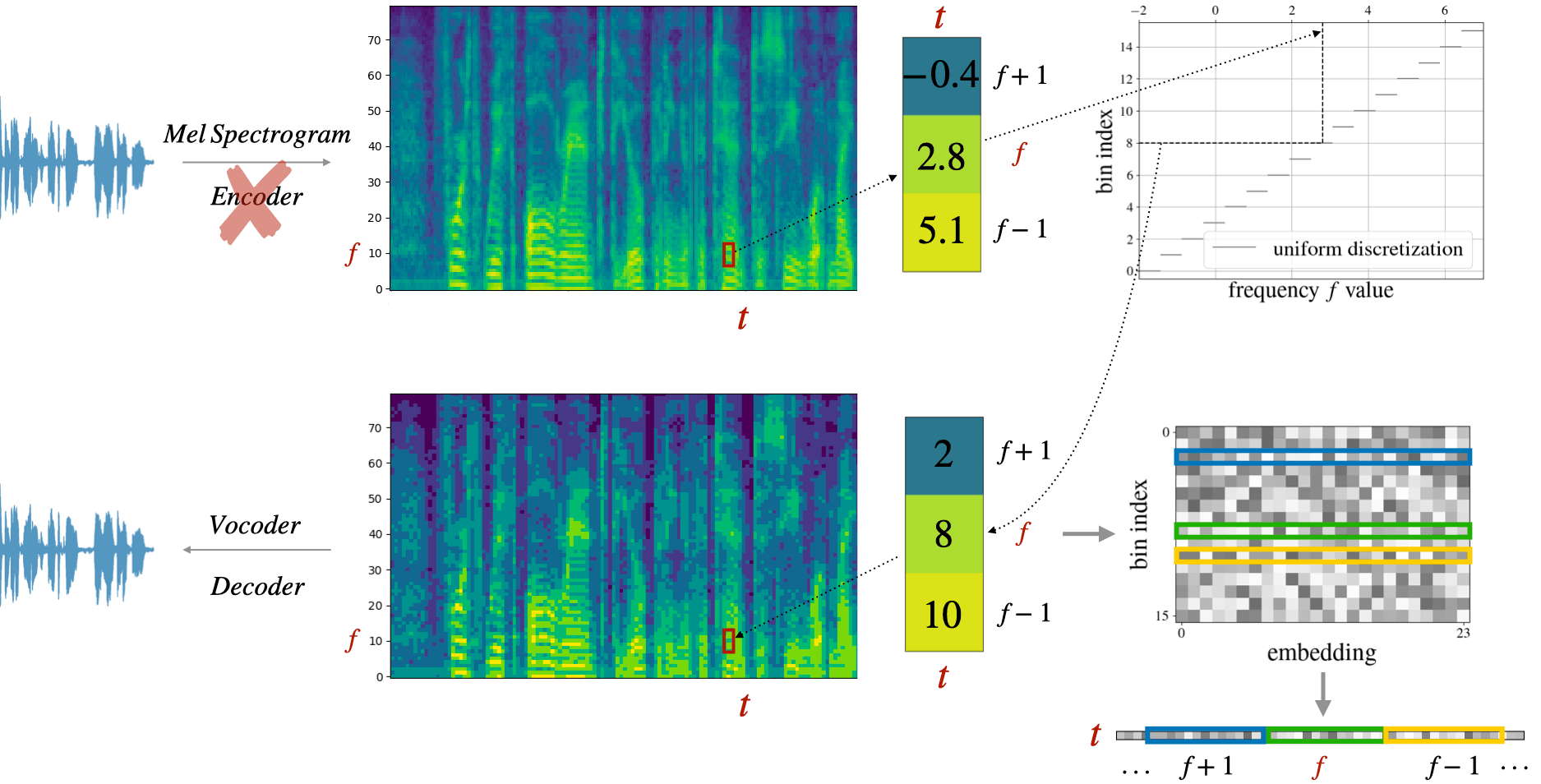
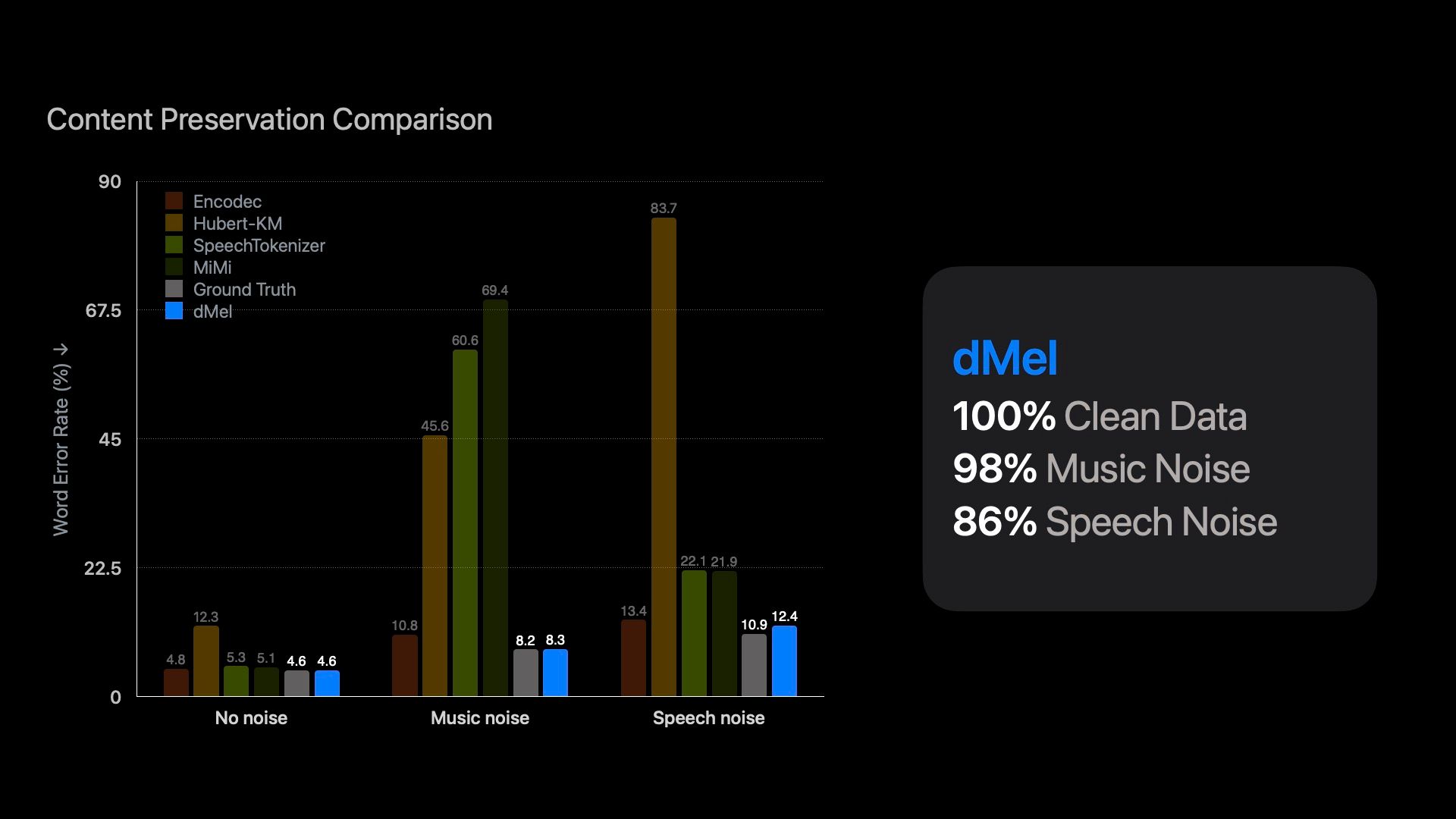
Massive language fashions have revolutionized pure language processing by leveraging self-supervised pretraining on huge textual information. Impressed by this success, researchers have investigated difficult speech tokenization strategies to discretize steady speech indicators in order that language modeling strategies will be utilized to speech information. Nevertheless, present approaches both mannequin semantic (content material) tokens, doubtlessly dropping acoustic data, or mannequin acoustic tokens, risking the lack of semantic (content material) data. Having a number of token sorts additionally complicates the structure and requires extra pretraining. Right here we present that discretizing mel-filterbank channels into discrete depth bins produces a easy illustration (dMel), that performs higher than different present speech tokenization strategies. Utilizing an LM-style transformer structure for speech-text modeling, we comprehensively consider totally different speech tokenization strategies on speech recognition (ASR) and speech synthesis (TTS). Our outcomes exhibit the effectiveness of dMel in reaching excessive efficiency on each duties inside a unified framework, paving the way in which for environment friendly and efficient joint modeling of speech and textual content.



{kind=link}