

Current paradigms for making certain AI security, similar to guardrail fashions and alignment coaching, typically compromise both inference effectivity or improvement flexibility. We introduce Disentangled Security Adapters (DSA), a novel framework addressing these challenges by decoupling safety-specific computations from a task-optimized base mannequin. DSA makes use of light-weight adapters that leverage the bottom mannequin’s inner representations, enabling numerous and versatile security functionalities with minimal influence on inference price. Empirically, DSA-based security guardrails considerably outperform comparably sized standalone fashions, notably enhancing hallucination detection (0.88 vs. 0.61 AUC on Summedits) and in addition excelling at classifying hate speech (0.98 vs. 0.92 on ToxiGen) and unsafe mannequin inputs and responses (0.93 vs. 0.90 on AEGIS2.0 & BeaverTails). Moreover, DSA-based security alignment permits dynamic, inference-time adjustment of alignment energy and a fine-grained trade-off between instruction following efficiency and mannequin security. Importantly, combining the DSA security guardrail with DSA security alignment facilitates context-dependent alignment energy, boosting security on StrongReject by 93% whereas sustaining 98% efficiency on MTBench — a complete discount in alignment tax of 8 proportion factors in comparison with commonplace security alignment fine-tuning. Total, DSA presents a promising path in the direction of extra modular, environment friendly, and adaptable AI security and alignment.
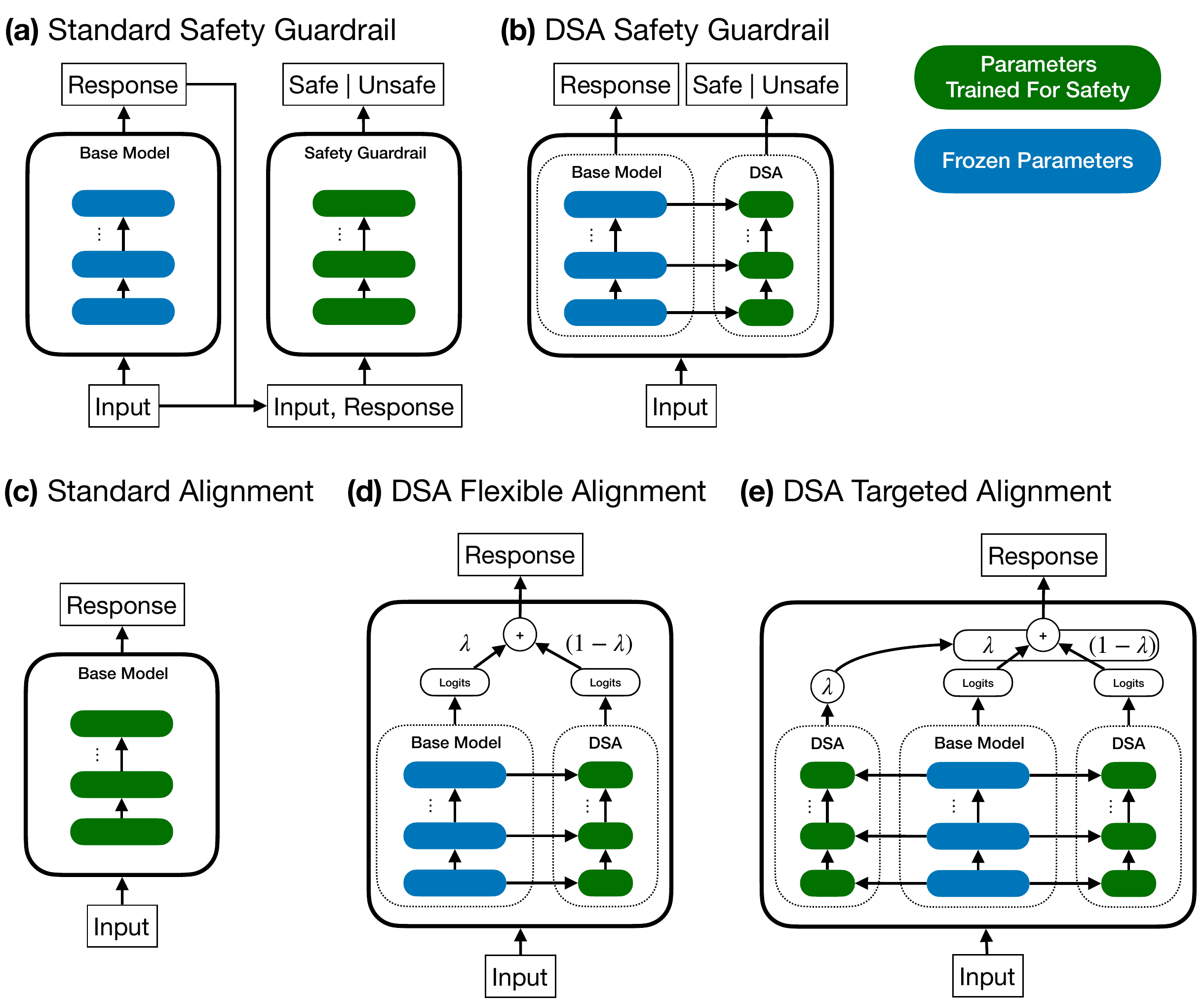
Determine 1: Overview of DSA structure and the way it compares to straightforward security strategies.

{kind=link}