
Once I introduced the Stub Networks in Digital Labs weblog submit on LinkedIn, I claimed it was the final chapter within the “hyperlinks in digital labs” saga. I used to be incorrect; right here comes the fourth a part of the digital hyperlinks trilogy – capturing “on the wire” visitors in digital networking labs.
Whereas community gadgets present visitors seize capabilities (normally tcpdump in disguise producing a .pcap file), it’s usually higher to seize the visitors outdoors of the system to see what the basis reason behind the issues you’re experiencing is likely to be.
Capturing Visitors on Libvirt Networks
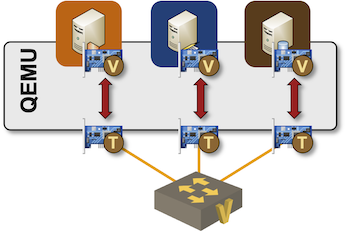
As mentioned in Hyperlinks in Digital Labs, netlab makes use of a libvirt community to create a LAN section, and libvirt implements networks with Linux bridges. Moreover, every VM wants an interface connected to that bridge. QEMU implements these attachments with faucet interfaces and shuffles visitors between the Linux faucet interfaces and emulated VM interfaces:
Capturing visitors generated by QEMU-powered digital machines related to a Linux bridge is trivial; let me stroll you thru an instance created with a easy netlab topology having three Linux VMs connected to a standard section:
netlab topology I used to check VM visitors seize
supplier: libvirt
defaults.system: linux
nodes: [ a, b, c ]
hyperlinks: [ a-b-c ]
After beginning the lab, we are able to see the Linux bridge and the related interfaces:
Displaying the record of libvirt networks
$ virsh net-list
Title State Autostart Persistent
----------------------------------------------------
default lively sure sure
vagrant-libvirt lively no sure
X_1 lively sure sure
Displaying the main points of our libvirt community
$ virsh net-info X_1
Title: X_1
UUID: 68ead5e5-8c9d-4c7a-a788-e0a673d258d2
Lively: sure
Persistent: sure
Autostart: sure
Bridge: virbr1
Displaying the interfaces connected to the Linux bridge
$ brctl present virbr1
bridge identify bridge id STP enabled interfaces
virbr1 8000.5254001743c2 no vgif_a_1
vgif_b_1
vgif_c_1
Now that we all know the names of the Linux interfaces serving the VM interfaces, we are able to seize visitors traversing a single interface or the entire LAN section.
For instance, when pinging A from B, we should always see the ICMP packets on vgif_a_1, vgif_b_1 and virbr1 however not on vgif_c_1:
Visitors captured on the QEMU faucet interfaces
$ sudo tcpdump -i vgif_a_1 -c 5 -vv ip
tcpdump: listening on vgif_a_1, link-type EN10MB (Ethernet), snapshot size 262144 bytes
16:59:13.835860 IP (tos 0x0, ttl 64, id 30891, offset 0, flags [DF], proto ICMP (1), size 84)
172.16.0.2 > 172.16.0.1: ICMP echo request, id 1670, seq 1, size 64
16:59:13.836114 IP (tos 0x0, ttl 64, id 3870, offset 0, flags [none], proto ICMP (1), size 84)
172.16.0.1 > 172.16.0.2: ICMP echo reply, id 1670, seq 1, size 64
16:59:14.845327 IP (tos 0x0, ttl 64, id 31728, offset 0, flags [DF], proto ICMP (1), size 84)
172.16.0.2 > 172.16.0.1: ICMP echo request, id 1670, seq 2, size 64
16:59:14.845685 IP (tos 0x0, ttl 64, id 4222, offset 0, flags [none], proto ICMP (1), size 84)
172.16.0.1 > 172.16.0.2: ICMP echo reply, id 1670, seq 2, size 64
16:59:15.869352 IP (tos 0x0, ttl 64, id 32258, offset 0, flags [DF], proto ICMP (1), size 84)
172.16.0.2 > 172.16.0.1: ICMP echo request, id 1670, seq 3, size 64
5 packets captured
6 packets obtained by filter
0 packets dropped by kernel
$ sudo tcpdump -i vgif_b_1 -c 3 -vv ip
tcpdump: listening on vgif_b_1, link-type EN10MB (Ethernet), snapshot size 262144 bytes
16:59:38.269277 IP (tos 0x0, ttl 64, id 43941, offset 0, flags [DF], proto ICMP (1), size 84)
172.16.0.2 > 172.16.0.1: ICMP echo request, id 1671, seq 6, size 64
16:59:38.269658 IP (tos 0x0, ttl 64, id 13403, offset 0, flags [none], proto ICMP (1), size 84)
172.16.0.1 > 172.16.0.2: ICMP echo reply, id 1671, seq 6, size 64
16:59:39.293336 IP (tos 0x0, ttl 64, id 44095, offset 0, flags [DF], proto ICMP (1), size 84)
172.16.0.2 > 172.16.0.1: ICMP echo request, id 1671, seq 7, size 64
3 packets captured
4 packets obtained by filter
0 packets dropped by kernel
$ sudo tcpdump -i vgif_c_1 -c 3 -vv ip
tcpdump: listening on vgif_c_1, link-type EN10MB (Ethernet), snapshot size 262144 bytes
^C
0 packets captured
0 packets obtained by filter
0 packets dropped by kernel
Visitors captured on the Linux bridge
$ sudo tcpdump -i virbr1 -c 3 -vv ip
tcpdump: listening on virbr1, link-type EN10MB (Ethernet), snapshot size 262144 bytes
16:59:50.557321 IP (tos 0x0, ttl 64, id 48456, offset 0, flags [DF], proto ICMP (1), size 84)
172.16.0.2 > 172.16.0.1: ICMP echo request, id 1671, seq 18, size 64
16:59:50.557723 IP (tos 0x0, ttl 64, id 19680, offset 0, flags [none], proto ICMP (1), size 84)
172.16.0.1 > 172.16.0.2: ICMP echo reply, id 1671, seq 18, size 64
16:59:51.581310 IP (tos 0x0, ttl 64, id 48532, offset 0, flags [DF], proto ICMP (1), size 84)
172.16.0.2 > 172.16.0.1: ICMP echo request, id 1671, seq 19, size 64
3 packets captured
4 packets obtained by filter
0 packets dropped by kernel
That Sounds Advanced
You’re proper. It’s. That’s why netlab supplies a handy wrapper across the virsh/brctl/tcpdump sequence. netlab seize command takes a node identify and an interface identify (utilizing the names utilized by community gadgets), finds the Linux interface related to the VM interface, and begins the tcpdump course of.
In our situation, we might merely use netlab seize a eth1 and add the tcpdump parameters:
Capturing visitors on the Ethernet interface of node A
$ netlab seize a eth1 -vv -c 3 ip
Beginning packet seize on a/eth1: sudo tcpdump -i vgif_a_1 -vv -c 3 ip
tcpdump: listening on vgif_a_1, link-type EN10MB (Ethernet), snapshot size 262144 bytes
17:09:00.382163 IP (tos 0x0, ttl 64, id 59350, offset 0, flags [DF], proto ICMP (1), size 84)
172.16.0.2 > 172.16.0.1: ICMP echo request, id 1671, seq 555, size 64
17:09:00.382460 IP (tos 0x0, ttl 64, id 29158, offset 0, flags [none], proto ICMP (1), size 84)
172.16.0.1 > 172.16.0.2: ICMP echo reply, id 1671, seq 555, size 64
17:09:01.406191 IP (tos 0x0, ttl 64, id 59681, offset 0, flags [DF], proto ICMP (1), size 84)
172.16.0.2 > 172.16.0.1: ICMP echo request, id 1671, seq 556, size 64
3 packets captured
4 packets obtained by filter
0 packets dropped by kernel
Capturing Container Visitors
You should use the same trick to seize the visitors of containers connected to a Docker community (or a Linux bridge). We’ll use the identical netlab topology with clab supplier (beginning Linux nodes as containers):
netlab container topology with a LAN section
supplier: clab
defaults.system: linux
nodes: [ a, b, c ]
hyperlinks: [ a-b-c ]
containerlab doesn’t use Docker networks. netlab has to create a Linux bridge and inform containerlab to attach the three containers to it:
Abbreviated containerlab topology file
identify: X
prefix: "clab"
topology:
nodes:
a:
form: linux
b:
form: linux
c:
form: linux
X_1:
form: bridge
hyperlinks:
- endpoints:
- "a:eth1"
- "X_1:a_eth1"
- endpoints:
- "b:eth1"
- "X_1:b_eth1"
- endpoints:
- "c:eth1"
- "X_1:c_eth1"
The container connections to the Linux bridge are carried out with vEth pairs. The topology is sort of similar to the one QEMU makes use of to attach digital machines to the Linux bridges; the one distinction is the mechanism used to implement the hyperlink between the VM/container interfaces and the Linux bridge interfaces.
We are able to thus use the brctl present command to show interfaces related to the X_1 bridge and use tcpdump to seize their visitors:
Interfaces related to the X_1 bridge
$ brctl present X_1
bridge identify bridge id STP enabled interfaces
X_1 8000.363f459a1c59 no a_eth1
b_eth1
c_eth1
Nevertheless, as we’re utilizing containers, we are able to do one thing higher: execute a Linux command instantly inside the container namespace. containerlab creates user-friendly community namespaces, and we are able to use the ip netns command to record the container interfaces and ip netns exec command to execute tcpdump inside a community namespace:
Container namespaces created by containerlab
$ ip netns
clab-X-b
clab-X-a
clab-X-c
Interfaces inside the container clab-X-a
$ sudo ip netns exec clab-X-a ip hyperlink
1: lo: mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
hyperlink/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
10093: eth0@if10094: mtu 1500 qdisc noqueue state UP mode DEFAULT group default
hyperlink/ether 02:42:c0:a8:79:65 brd ff:ff:ff:ff:ff:ff link-netnsid 0
10100: eth1@if10099: mtu 1500 qdisc noqueue state UP mode DEFAULT group default
hyperlink/ether aa:c1:ab:8f:5c:6a brd ff:ff:ff:ff:ff:ff link-netnsid 0
Capturing visitors on eth1 interface of container clab-X-a
$ sudo ip netns exec clab-X-a tcpdump -i eth1 -c 3 -vv ip
tcpdump: listening on eth1, link-type EN10MB (Ethernet), snapshot size 262144 bytes
17:21:43.521792 IP (tos 0x0, ttl 64, id 2506, offset 0, flags [DF], proto ICMP (1), size 84)
172.16.0.2 > 172.16.0.1: ICMP echo request, id 12, seq 0, size 64
17:21:43.521825 IP (tos 0x0, ttl 64, id 65382, offset 0, flags [none], proto ICMP (1), size 84)
172.16.0.1 > 172.16.0.2: ICMP echo reply, id 12, seq 0, size 64
17:21:44.522130 IP (tos 0x0, ttl 64, id 2725, offset 0, flags [DF], proto ICMP (1), size 84)
172.16.0.2 > 172.16.0.1: ICMP echo request, id 12, seq 1, size 64
3 packets captured
4 packets obtained by filter
0 packets dropped by kernel
Please observe that the ip hyperlink or tcpdump instructions usually are not executed inside the container however solely inside the container’s community namespace. The instructions executed with the ip netns exec command don’t must be a part of the container picture.
But once more, you need to use the netlab seize command to begin tcpdump inside the desired container community namespace:
Utilizing netlab seize to seize container visitors
$ netlab seize a eth1
Beginning packet seize on a/eth1: sudo ip netns exec clab-X-a tcpdump -i eth1 -l -v
tcpdump: listening on eth1, link-type EN10MB (Ethernet), snapshot size 262144 bytes
17:22:43.891278 IP (tos 0x0, ttl 64, id 14171, offset 0, flags [DF], proto ICMP (1), size 84)
172.16.0.2 > 172.16.0.1: ICMP echo request, id 13, seq 0, size 64
17:22:43.891289 IP (tos 0x0, ttl 64, id 6813, offset 0, flags [none], proto ICMP (1), size 84)
172.16.0.1 > 172.16.0.2: ICMP echo reply, id 13, seq 0, size 64
17:22:44.891564 IP (tos 0x0, ttl 64, id 14377, offset 0, flags [DF], proto ICMP (1), size 84)
172.16.0.2 > 172.16.0.1: ICMP echo request, id 13, seq 1, size 64
Capturing Visitors on Level-to-Level Container Hyperlinks
As described in Level-to-Level Hyperlinks in Digital Labs, containerlab creates direct hyperlinks between containers:
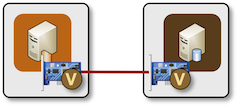
Direct point-to-point hyperlink between two containers
Because the containers are now not related to a Linux bridge, we can not seize the visitors on a connecting section. The endpoints of the vEth pairs are additionally not seen within the “international” community namespace, however we already know the trick to make use of: use ip netns exec to execute tcpdump inside the community namespace.
What About Libvirt Level-to-Level UDP Tunnels
Capturing visitors on container-to-container hyperlinks is trivial. Can we do the identical for VM-to-VM hyperlinks carried out as QEMU UDP tunnels? We haven’t discovered a great resolution but; the UDP tunnels don’t use Linux interfaces, so there’s no handy interface we might use within the -i parameter of the tcpdump command.
In idea, one might:
- Seize the VM visitors based mostly on UDP port numbers right into a
.pcapfile - Modify the
.pcapfile with editcap to take away the primary 42 bytes of every packet (Ethernet/IP/UDP headers) - Learn the modified
.pcapfile with tcpdump or wireshark
This strategy works however doesn’t show the packets in actual time. When you’ve got a greater concept, please go away a remark.
Revision Historical past
- 2025-03-04
- Added tips that could Edgeshark based mostly on the remark by Jaap de Vos



{kind=link}