

Apple researchers are advancing AI and ML via elementary analysis, and to assist the broader analysis group and assist speed up progress on this area, we share a lot of our analysis via publications and engagement at conferences. This week, the IEEE/CVF Convention on Pc Imaginative and prescient and Sample Recognition (CVPR), will happen in Nashville, Tennessee. Apple is proud to as soon as once more take part on this necessary occasion for the group and to be an business sponsor.
On the principal convention and related workshops, Apple researchers will current new analysis throughout numerous subjects in laptop imaginative and prescient, together with imaginative and prescient language fashions, 3D photogrammetry, giant multimodal fashions, and video diffusion fashions.
CVPR attendees will have the ability to expertise demonstrations of Apple’s ML analysis in our sales space #1217 throughout exhibition hours. Apple can be sponsoring and taking part in numerous affinity group-hosted occasions that assist underrepresented teams within the ML group. A complete overview of Apple’s participation in and contributions to CVPR 2025 could be discovered right here, and a choice of highlights observe beneath.
FastVLM: Environment friendly Imaginative and prescient encoding for Imaginative and prescient Language Fashions
The efficiency of Imaginative and prescient Language Fashions (VLMs) improves because the decision of enter photos will increase, however widespread visible encoders reminiscent of ViTs grow to be inefficient at excessive resolutions due to the big variety of tokens and excessive encoding latency. For a lot of manufacturing use-cases, VLMs should be each correct and environment friendly to fulfill the low-latency calls for of real-time functions and run on gadget for privacy-preserving AI experiences.
At CVPR 2025, Apple researchers will current FastVLM: Environment friendly Imaginative and prescient encoding for Imaginative and prescient Language Fashions. The work shares FastViTHD: a novel hybrid imaginative and prescient encoder, designed to output fewer tokens and considerably scale back encoding time for high-resolution photos. Utilizing this environment friendly encoder for high-res enter, FastVLM considerably improves accuracy-latency trade-offs with a easy design. FastVLM delivers correct, quick, and environment friendly visible question processing, making it appropriate for powering real-time functions on-device, and the inference code, mannequin checkpoints, and an iOS/macOS demo app based mostly on MLX can be found right here.
Matrix3D: Giant Photogrammetry Mannequin All-in-One
Photogrammetry permits 3D scenes to be constructed from 2D photos, however the conventional method has two limitations. First, it normally requires a dense assortment of 2D photos to attain strong and correct 3D reconstruction. Second, the pipeline typically entails a number of processing numerous impartial duties – like characteristic detection, structure-from-motion, and multi-view stereo – that aren’t correlated or collectively optimized with each other.
In a Spotlight presentation at CVPR, Apple researchers will current a brand new method to this problem that overcomes these prior limitations. The paper Matrix3D: Giant Photogrammetry Mannequin All-in-Oneshares a single unified mannequin that performs a number of photogrammetry subtasks, together with pose estimation, depth prediction, and novel view synthesis. Matrix3D makes use of a multi-modal diffusion transformer (DiT) to combine transformations throughout a number of modalities, reminiscent of photos, digital camera parameters, and depth maps. The multimodal coaching for this method integrates a masks studying technique that allows full-modality coaching even with partially full knowledge, reminiscent of bi-modality knowledge of image-pose and image-depth pairs, which considerably will increase the pool of obtainable coaching knowledge. Matrix3D demonstrates state-of-the-art efficiency in pose estimation and novel view synthesis duties, and, it affords fine-grained management via multi-round interactions, making it an modern instrument for 3D content material creation. Code is accessible right here.
Multimodal Autoregressive Pre-Coaching of Giant Imaginative and prescient Encoders
Giant multimodal fashions are generally skilled by pairing a big language decoder with a imaginative and prescient encoder. These imaginative and prescient encoders are normally pre-trained with a discriminative goal, reminiscent of contrastive loss, however this creates a mismatch between pre-training and the generative autoregressive downstream job. Following the success of autoregressive approaches for coaching language fashions, autoregressive picture fashions have been proven to pre-train sturdy and scalable imaginative and prescient encoders.
In a Spotlight presentation at CVPR 2025, Apple ML researchers will share Multimodal Autoregressive Pre-Coaching of Giant Imaginative and prescient Encoders, which describes AIMv2, a household of huge, sturdy imaginative and prescient encoders pre-trained with a multimodal autoregressive goal. A multimodal decoder generates each uncooked patches and textual content tokens, main these fashions to excel not solely at multimodal duties but in addition in visible recognition benchmarks reminiscent of localization, grounding, and classification. The work additionally exhibits that AIMv2 fashions are environment friendly to coach, outperforming the present state-of-the-art with considerably fewer samples seen throughout pre-training. Code and mannequin checkpoints can be found right here.
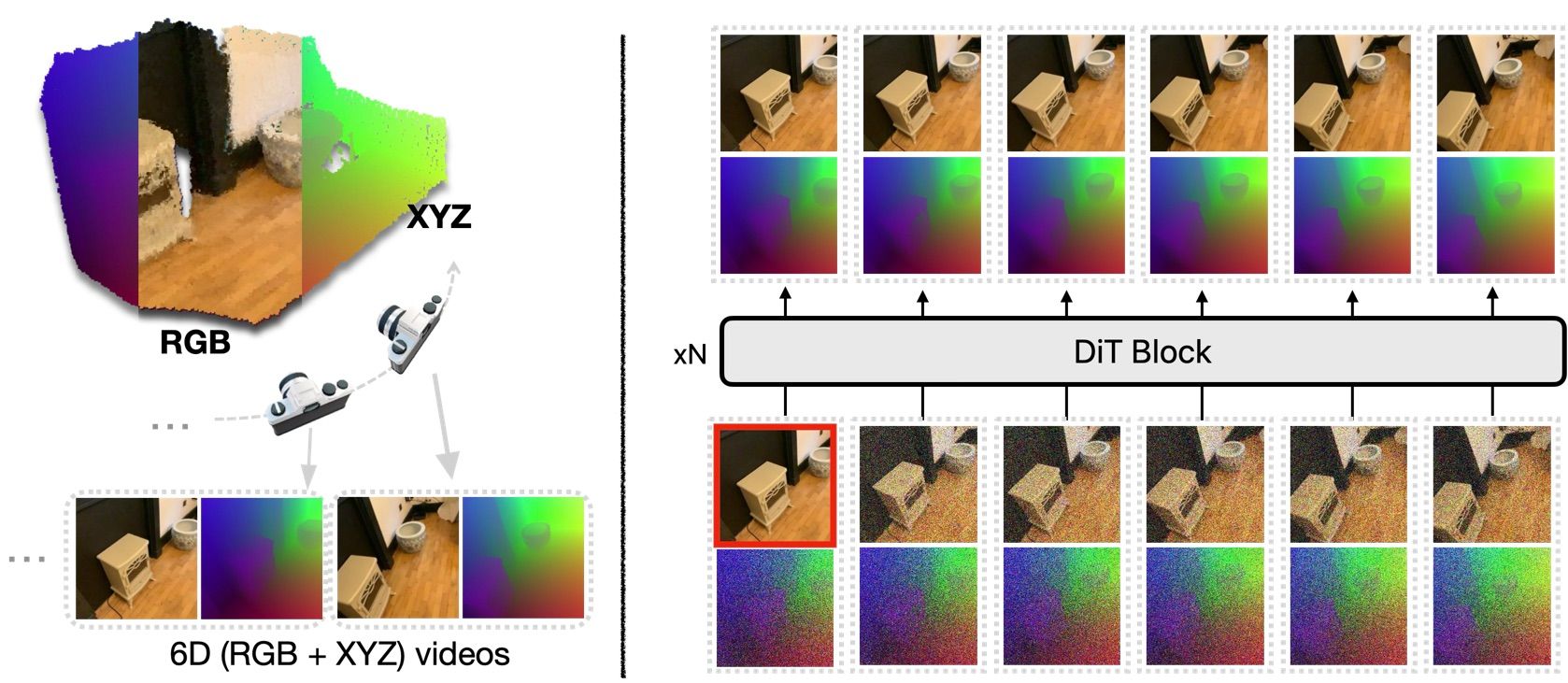
World-Constant Video Diffusion with Express 3D Modeling
Diffusion fashions have grow to be the dominant paradigm for sensible picture and video technology, however these fashions nonetheless wrestle with effectively and explicitly producing 3D-consistent content material. Historically, these strategies implicitly study 3D consistency by producing solely RGB frames, which may result in artifacts and inefficiencies in coaching.
In a Spotlight presentation at CVPR, Apple researchers will share World-Constant Video Diffusion with Express 3D Modeling, which particulars a brand new method that addresses these challenges. This system, World-consistent Video Diffusion (WVD), trains a diffusion transformer to study the joint distribution of each RGB (shade) and XYZ (coordinates in area) frames. Consequently, the mannequin can adapt to a number of duties with a versatile inpainting functionality. For instance, given ground-truth RGB, the mannequin can estimate XYZ frames; or, it could possibly generate novel RGB frames utilizing XYZ projections alongside a specified digital camera trajectory. With this flexibility, WVD unifies duties like single-image-to-3D technology, multi-view stereo, and camera-controlled video technology.
Demonstrating ML Analysis within the Apple Sales space
Throughout exhibition hours, CVPR attendees will have the ability to work together with stay demos of Apple ML analysis in sales space #1217, together with FastVLM, described above.
Supporting the ML Analysis Group
Apple is dedicated to supporting underrepresented teams within the ML group. We’re proud to once more sponsor a number of affinity teams internet hosting occasions onsite at CVPR, together with LatinX in CV (LXCV is a sub-group of LXAI) (workshop on June 11), and Ladies in Pc Imaginative and prescient (WiCV) (workshop on June 12).
Study Extra about Apple ML Analysis at CVPR 2025
CVPR brings collectively the group of researchers advancing the state-of-the-art in laptop imaginative and prescient, and Apple is proud to once more share modern new analysis on the occasion and join with the group attending it. This publish highlights only a choice of the works Apple ML researchers will current at CVPR 2025, and a complete overview and schedule of our participation could be discovered right here.

{kind=link}