
{kind=link}
whether or not GenAI is simply hype or exterior noise. I additionally thought this was hype, and I might sit this one out till the mud cleared. Oh, boy, was I unsuitable. GenAI has real-world functions. It additionally generates income for corporations, so we anticipate corporations to speculate closely in analysis. Each time a know-how disrupts one thing, the method usually strikes by way of the next phases: denial, anger, and acceptance. The identical factor occurred when computer systems have been launched. If we work within the software program or {hardware} area, we would want to make use of GenAI sooner or later.
On this article, I cowl the right way to energy your software with giant Language Fashions (LLMs) and focus on the challenges I confronted whereas organising LLMs. Let’s get began.
1. Begin by defining your use case clearly
Earlier than leaping onto LLM, we should always ask ourselves some questions
a. What drawback will my LLM resolve?
b. Can my software do with out LLM
c. Do I’ve sufficient sources and compute energy to develop and deploy this software?
Slim down your use case and doc it. In my case, I used to be engaged on an information platform as a service. We had tons of data on wikis, Slack, workforce channels, and so on. We wished a chatbot to learn this data and reply questions on our behalf. The chatbot would reply buyer questions and requests on our behalf, and if clients have been nonetheless sad, they’d be routed to an Engineer.
2. Select your mannequin

You may have two choices: Prepare your mannequin from scratch or use a pre-trained mannequin and construct on high of it. The latter would work normally until you’ve gotten a selected use case. Coaching your mannequin from scratch would require large computing energy, vital engineering efforts, and prices, amongst different issues. Now, the following query is, which pre-trained mannequin ought to I select? You’ll be able to choose a mannequin based mostly in your use case. 1B parameter mannequin has fundamental data and sample matching. Use instances might be restaurant evaluations. The 10B parameter mannequin has wonderful data and may comply with directions like a meals order chatbot. A 100B+ parameters mannequin has wealthy world data and sophisticated reasoning. This can be utilized as a brainstorming companion. There are a lot of fashions out there, resembling Llama and ChatGPT. After getting a mannequin in place, you’ll be able to broaden on the mannequin.
3. Improve the mannequin as per your knowledge
After getting a mannequin in place, you’ll be able to broaden on the mannequin. The LLM mannequin is skilled on usually out there knowledge. We need to prepare it on our knowledge. Our mannequin wants extra context to offer solutions. Let’s assume we need to construct a restaurant chatbot that solutions buyer questions. The mannequin doesn’t know data explicit to your restaurant. So, we need to present the mannequin some context. There are a lot of methods we will obtain this. Let’s dive into a few of them.
Immediate Engineering
Immediate engineering includes augmenting the enter immediate with extra context throughout inference time. You present context in your enter quote itself. That is the simplest to do and has no enhancements. However this comes with its disadvantages. You can not give a big context contained in the immediate. There’s a restrict to the context immediate. Additionally, you can not anticipate the consumer to all the time present full context. The context is likely to be in depth. It is a fast and straightforward answer, nevertheless it has a number of limitations. Here’s a pattern immediate engineering.
“Classify this evaluate
I really like the film
Sentiment: ConstructiveClassify this evaluate
I hated the film.
Sentiment: DetrimentalClassify the film
The ending was thrilling”
Strengthened Studying With Human Suggestions (RLHF)

RLHF is without doubt one of the most-used strategies for integrating LLM into an software. You present some contextual knowledge for the mannequin to be taught from. Right here is the stream it follows: The mannequin takes an motion from the motion area and observes the state change within the atmosphere because of that motion. The reward mannequin generated a reward rating based mostly on the output. The mannequin updates its weight accordingly to maximise the reward and learns iteratively. As an illustration, in LLM, motion is the following phrase that the LLM generates, and the motion area is the dictionary of all potential phrases and vocabulary. The atmosphere is the textual content context; the State is the present textual content within the context window.
The above rationalization is extra like a textbook rationalization. Let’s take a look at a real-life instance. You need your chatbot to reply questions relating to your wiki paperwork. Now, you select a pre-trained mannequin like ChatGPT. Your wikis might be your context knowledge. You’ll be able to leverage the langchain library to carry out RAG. You’ll be able to Here’s a pattern code in Python
from langchain.document_loaders import WikipediaLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
import os
# Set your OpenAI API key
os.environ["OPENAI_API_KEY"] = "your-openai-key-here"
# Step 1: Load Wikipedia paperwork
question = "Alan Turing"
wiki_loader = WikipediaLoader(question=question, load_max_docs=3)
wiki_docs = wiki_loader.load()
# Step 2: Break up the textual content into manageable chunks
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
split_docs = splitter.split_documents(wiki_docs)
# Step 3: Embed the chunks into vectors
embeddings = OpenAIEmbeddings()
vector_store = FAISS.from_documents(split_docs, embeddings)
# Step 4: Create a retriever
retriever = vector_store.as_retriever(search_type="similarity", search_kwargs={"okay": 3})
# Step 5: Create a RetrievalQA chain
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # You may also strive "map_reduce" or "refine"
retriever=retriever,
return_source_documents=True,
)
# Step 6: Ask a query
query = "What did Alan Turing contribute to laptop science?"
response = qa_chain(query)
# Print the reply
print("Reply:", response["result"])
print("n--- Sources ---")
for doc in response["source_documents"]:
print(doc.metadata)4. Consider your mannequin
Now, you’ve gotten added RAG to your mannequin. How do you verify in case your mannequin is behaving accurately? This isn’t a code the place you give some enter parameters and obtain a hard and fast output, which you’ll be able to check in opposition to. Since it is a language-based communication, there might be a number of appropriate solutions. However what you’ll be able to know for certain is whether or not the reply is inaccurate. There are a lot of metrics you’ll be able to check your mannequin in opposition to.
Consider manually
You’ll be able to frequently consider your mannequin manually. As an illustration, we had built-in a Slack chatbot that was enhanced with RAG utilizing our wikis and Jira. As soon as we added the chatbot to the Slack channel, we initially shadowed its responses. The purchasers couldn’t view the responses. As soon as we gained confidence, we made the chatbot publicly seen to the purchasers. We evaluated its response manually. However it is a fast and imprecise strategy. You can not achieve confidence from such guide testing. So, the answer is to check in opposition to some benchmark, resembling ROUGE.
Consider with ROUGE rating.
ROUGE metrics are used for textual content summarization. Rouge metrics examine the generated abstract with reference summaries utilizing totally different ROUGE metrics. Rouge metrics consider the mannequin utilizing recall, precision, and F1 scores. ROUGE metrics are available numerous sorts, and poor completion can nonetheless lead to a very good rating; therefore, we consult with totally different ROUGE metrics. For some context, a unigram is a single phrase; a bigram is 2 phrases; and an n-gram is N phrases.
ROUGE-1 Recall = Unigram matches/Unigram in reference
ROUGE-1 Precision = Unigram matches/Unigram in generated output
ROUGE-1 F1 = 2 * (Recall * Precision / (Recall + Precision))
ROUGE-2 Recall = Bigram matches/bigram reference
ROUGE-2 Precision = Bigram matches / Bigram in generated output
ROUGE-2 F1 = 2 * (Recall * Precision / (Recall + Precision))
ROUGE-L Recall = Longest widespread subsequence/Unigram in reference
ROUGE-L Precision = Longest widespread subsequence/Unigram in output
ROUGE-L F1 = 2 * (Recall * Precision / (Recall + Precision))
For instance,
Reference: “It’s chilly outdoors.”
Generated output: “It is extremely chilly outdoors.”
ROUGE-1 Recall = 4/4 = 1.0
ROUGE-1 Precision = 4/5 = 0.8
ROUGE-1 F1 = 2 * 0.8/1.8 = 0.89
ROUGE-2 Recall = 2/3 = 0.67
ROUGE-2 Precision = 2/4 = 0.5
ROUGE-2 F1 = 2 * 0.335/1.17 = 0.57
ROUGE-L Recall = 2/4 = 0.5
ROUGE-L Precision = 2/5 = 0.4
ROUGE-L F1 = 2 * 0.335/1.17 = 0.44
Scale back trouble with the exterior benchmark
The ROUGE Rating is used to grasp how mannequin analysis works. Different benchmarks exist, just like the BLEU Rating. Nonetheless, we can not virtually construct the dataset to judge our mannequin. We are able to leverage exterior libraries to benchmark our fashions. Essentially the most generally used are the GLUE Benchmark and SuperGLUE Benchmark.
5. Optimize and deploy your mannequin
This step won’t be essential, however decreasing computing prices and getting sooner outcomes is all the time good. As soon as your mannequin is prepared, you’ll be able to optimize it to enhance efficiency and cut back reminiscence necessities. We’ll contact on just a few ideas that require extra engineering efforts, data, time, and prices. These ideas will aid you get acquainted with some strategies.
Quantization of the weights
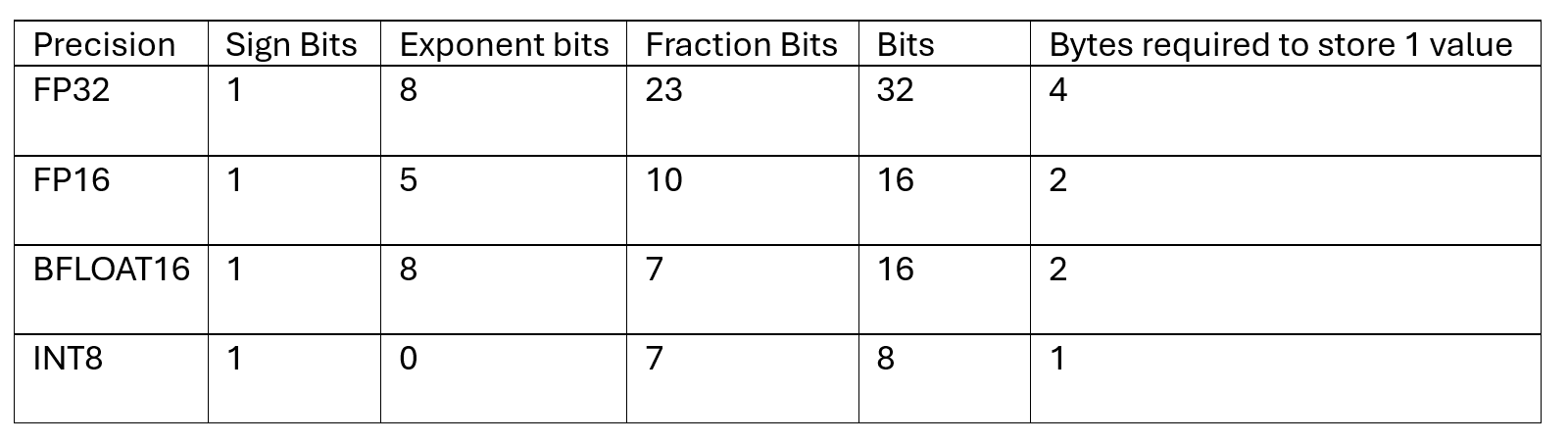
Fashions have parameters, inside variables inside a mannequin which can be discovered from knowledge throughout coaching and whose values decide how the mannequin makes predictions. 1 parameter often requires 24 bytes of processor reminiscence. So, for those who select 1B, parameters would require 24 GB of processor reminiscence. Quantization converts the mannequin weights from higher-precision floating-point numbers to lower-precision floating-point numbers for environment friendly storage. Altering the storage precision can considerably have an effect on the variety of bytes required to retailer a single worth of the load. The desk beneath illustrates totally different precisions for storing weights.
Pruning
Pruning includes eradicating weights in a mannequin which can be much less essential and have little affect, resembling weights equal to or near zero. Some strategies of pruning are
a. Full mannequin retraining
b. PEFT like LoRA
c. Submit-training.
Conclusion
To conclude, you’ll be able to select a pre-trained mannequin, resembling ChatGPT or FLAN-T5, and construct on high of it. Constructing your pre-trained mannequin requires experience, sources, time, and finances. You’ll be able to fine-tune it as per your use case if wanted. Then, you need to use your LLM to energy functions and tailor them to your software use case utilizing strategies like RAG. You’ll be able to consider your mannequin in opposition to some benchmarks to see if it behaves accurately. You’ll be able to then deploy your mannequin.