
{kind=link}
If in case you have simply began to be taught machine studying, likelihood is you may have already heard a few Determination Tree. Whilst you could not presently concentrate on its working, know that you’ve got undoubtedly used it in some kind or the opposite. Determination Timber have lengthy powered the backend of a few of the hottest companies accessible globally. Whereas there are higher alternate options accessible now, resolution bushes nonetheless maintain their significance on the earth of machine studying.
To present you a context, a choice tree is a supervised machine studying algorithm used for each classification and regression duties. Determination tree evaluation includes completely different selections and their potential outcomes, which assist make choices simply primarily based on sure standards, as we’ll talk about later on this weblog.
On this article, we’ll undergo what resolution bushes are in machine studying, how the choice tree algorithm works, their benefits and downsides, and their functions.
What’s Determination Tree?
A call tree is a non-parametric machine studying algorithm, which implies that it makes no assumptions concerning the relationship between enter options and the goal variable. Determination bushes can be utilized for classification and regression issues. A call tree resembles a circulation chart with a hierarchical tree construction consisting of:
- Root node
- Branches
- Inner nodes
- Leaf nodes

Varieties of Determination Timber
There are two completely different sorts of resolution bushes: classification and regression bushes. These are typically each known as CART (Classification and Regression Timber). We’ll speak about each briefly on this part.
- Classification Timber: A classification tree predicts categorical outcomes. Because of this it classifies the info into classes. The tree will then guess which class the brand new pattern belongs in. For instance, a classification tree could output whether or not an e mail is “Spam” or “Not Spam” primarily based on the options of the sender, topic and content material.
- Regression Timber: A regression tree is used when the goal variable is steady. This implies predicting a numerical worth versus a categorical worth. That is completed by averaging the values of that leaf. For instance, a regression tree may predict the very best worth of a home; the options could possibly be dimension, space, variety of bedrooms, and placement.
This algorithm usually makes use of ‘Gini impurity’ or ‘Entropy’ to establish the best attribute for a node break up. Gini impurity measures how typically a randomly chosen attribute is misclassified. The decrease the worth, the higher the break up can be for that attribute. Entropy is a measure of dysfunction or randomness within the dataset, so the decrease the worth of entropy for an attribute, the extra fascinating it’s for tree break up, and can result in extra predictable splits.
Equally, in apply, we’ll select the sort through the use of both DecisionTreeClassifier or DecisionTreeRegressor for classification and regression:
from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor
# Instance classifier (e.g., predict emails are spam or not)
clf = DecisionTreeClassifier(max_depth=3, random_state=42)
# Instance regressor (e.g., predict home costs)
reg = DecisionTreeRegressor(max_depth=3)Data Acquire and Gini Index in Determination Tree
So far, we now have mentioned the essential instinct and method of how a choice tree works. So, now let’s talk about the choice measures of the choice tree, which in the end assist in choosing the best node for the splitting course of. For that, we now have two standard approaches we’ll talk about beneath:
1. Data Acquire
Data Acquire is the measure of effectiveness of a specific attribute in decreasing the entropy within the dataset. This helps in choosing probably the most informative options for splitting the info, resulting in a extra correct & environment friendly mannequin.
So, suppose S is a set of situations and A is an attribute. Sv is the subset of S, and V represents a person worth of that attribute. A can take one worth from the set of (A), which is the set of all potential values for that attribute.

Entropy: Within the context of resolution bushes, entropy is the measure of dysfunction or randomness within the dataset. It’s most when the lessons are evenly distributed and reduces when the distribution turns into extra homogeneous. So, a node with low entropy means lessons are largely comparable or pure inside that node.
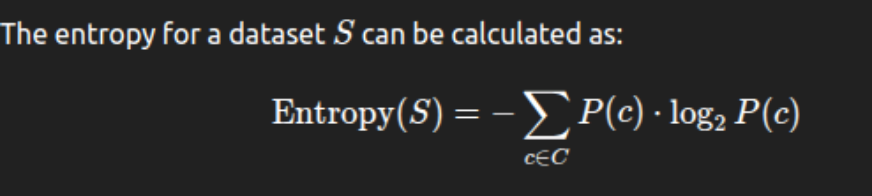
The place P(c) is the likelihood of lessons within the set S and C is the set of all lessons.
Instance: If we need to resolve whether or not to play tennis or not primarily based on the climate situations: Outlook and Temperature.
Outlook has 3 values: Sunny, Overcast, Rain
Temperature has 3 values: Scorching, Gentle, Chilly, and
Play Tennis consequence has 2 values: Sure or No.
| Outlook | Play Tennis | Rely |
|---|---|---|
| Sunny | No | 3 |
| Sunny | Sure | 2 |
| Overcast | Sure | 4 |
| Rain | No | 1 |
| Rain | Sure | 4 |
Calculating Data Acquire
Now we’ll calculate the Data when the break up is predicated on Outlook.
Step 1: Entropy of Total Dataset S
So, the entire variety of situations in S is 14, and their distribution is:
The entropy of S can be:
Entropy(S) = -(9/14 log2(9/14) + 5/14 log2(5/14) = 0.94
Step 2: Entropy for the subset primarily based on outlook
Now, let’s break the info factors into subsets primarily based on the Outlook distribution, so:
Sunny (5 information: 2 Sure and three No):
Entropy(Sunny)= -(⅖ log2(⅖)+ ⅗ log2(⅗)) =0.97
Overcast (4 information: 4 Sure, 0 No):
Entropy(Overcast) = 0 (because it’s a pure attribute, as all values are the identical)
Rain (5 information: 4 Sure, 1 No):
Entropy(Rain) = -(⅘ log2(⅘)+ ⅕ log2(⅕)) = 0.72
Step 3: Calculate Data Acquire
Now we’ll calculate data achieve primarily based on outlook:
Acquire(S,Outlook) = Entropy(S) – (5/14 * Entropy(Sunny) + 4/14 * Entropy(Overcast) + 5/14 * Entropy(Rain))
Acquire(S,Outlook) = 0.94-(5/14 * 0.97+ 4/14 * 0+ 5/14 * 0.72) = 0.94-0.603=0.337
So the Data Acquire for the Outlook attribute is 0.337
The Outlook attribute right here signifies it’s considerably efficient in deriving the answer. Nonetheless, it nonetheless leaves some uncertainty about the suitable consequence.
2. Gini Index
Similar to Data Acquire, the Gini Index is used to resolve the perfect function for splitting the info, nevertheless it operates otherwise. Gini Index is a metric to measure how typically a randomly chosen factor could be incorrectly recognized or impure (how blended the lessons are in a subset of knowledge). So, the upper the worth of the Gini Index for an attribute, the much less doubtless it’s to be chosen for the info break up. Subsequently, an attribute with the next Gini index worth is most popular in such resolution bushes.

The place:
m is the variety of lessons within the dataset and
P(i) is the likelihood of sophistication i within the dataset S.
For instance, if we now have a binary classification downside with lessons “Sure” and “No”, then the likelihood of every class is the fraction of situations in every class. The Gini Index ranges from 0, as completely pure, and 0.5, as most impurity for binary classification.
Subsequently, Gini=0 implies that all situations within the subset belong to the identical class, and Gini=0.5 means; the situations are equal proportions of all lessons.
Instance: If we need to resolve whether or not to play tennis or not primarily based on the climate situations: Outlook, and Temperature.
Outlook has 3 values: Sunny, Overcast, Rain
Temperature has 3 values: Scorching, Gentle, Chilly, and
Play Tennis consequence has 2 values: Sure or No.
|
Outlook
|
Play Tennis
|
Rely
|
|
Sunny
|
No
|
3
|
|
Sunny
|
Sure
|
2
|
|
Overcast
|
Sure
|
4
|
|
Rain
|
No
|
1
|
|
Rain
|
Sure
|
4
|
Calculating Gini Index
Now we’ll calculate the Gini Index when the break up is predicated on Outlook.
Step 1: Gini Index of Total Dataset S
So, the entire variety of situations in S is 14, and their distribution is:
The Gini Index of S can be:
P(Sure) = 9/14, P(No) = 5.14
Acquire(S)= 1-((9/14)^2 + (5/14)^2)
Acquire(S) = 1-(0.404_0.183) = 1- 0.587 = 0.413
Step 2: Gini Index for every subset primarily based on Outlook
Now, let’s break the info factors into subsets primarily based on the Outlook distribution, so:
Sunny(5 information: 2 Sure and three No):
P(Sure)=⅖, P(No) = ⅗
Gini(Sunny) = 1-((⅖)^2 +(⅗)^2) = 0.48
Overcast (4 information: 4 Sure, 0 No):
Since all situations on this subset are “Sure”, the Gini Index is:
Gini(Overcast) = 1-(4/4)^2 +(0/4)^2)= 1-1= 0
Rain (5 information: 4 Sure, 1 No):
P(Sure)=⅘, P(No)=⅕
Gini(Rain) = 1-((⅘ )^2 +⅕ )^2) = 0.32
Overcast (4 information: 4 Sure, 0 No):
Since all situations on this subset are “Sure”, the Gini Index is:
Gini(Overcast) = 1-(4/4)^2 +(0/4)^2)= 1-1= 0
Rain (5 information: 4 Sure, 1 No):
P(Sure)=⅘, P(No)=⅕
Gini(Rain) = 1-((⅘ )^2 +⅕ )^2) = 0.32
Step 3: Weighted Gini Index for Cut up
Now, we calculate the Weighted Gini Index for the break up primarily based on Outlook. This would be the Gini Index for your entire dataset after the break up.
Weighted Gini(S,Outlook)= 5/14 * Gini(Sunny) + 4/14 * Gini(Overcast) + 5/14 * (Gini(Rain)
Weighted Gini(S,Outlook)= 5/14 * 0.48+ 4/14 *0 + 5/14 * 0.32 = 0.286
Step 4: Gini Acquire
Gini Acquire can be calculated because the discount within the Gini Index after the break up. So,
Gini Acquire(S,Outlook)=Gini(S)−Weighted Gini(S,Outlook)
Gini Acquire(S,Outlook) = 0.413 – 0.286 = 0.127
So, the Gini Acquire for the Outlook attribute is 0.127. Because of this through the use of Outlook as a splitting node, the impurity of the dataset might be decreased by 0.127. This means the effectiveness of this function in classifying the info.
How Does a Determination Tree Work?
As mentioned, a choice tree is a supervised machine studying algorithm that can be utilized for each regression and classification duties. A call tree begins with the collection of a root node utilizing one of many splitting standards – data achieve or gini index. So, constructing a choice tree includes recursive splitting the coaching information till the likelihood of distinction of outcomes in every department turns into most. The choice tree algorithm proceeds top-down from the basis. Right here is the way it works:
- Begin with the Root Node with all coaching samples.
- Select the perfect attribute to separate the info. The perfect function for the break up would be the one that offers probably the most variety of pure youngster nodes(that means the place the info factors belong to the identical class). This may be measured both by data achieve or the Gini index.
- Splitting the info into small subsets in line with the chosen function with max data achieve or minimal Gini index, creating additional pure youngster nodes till the ultimate outcomes are homogenous or from the identical class.
- The ultimate step stops the tree from additional rising when the situation is met, often known as the storing standards. It happens if or when:
- All the info within the node belongs to the identical class or is a pure node.
- No additional break up stays.
- A most depth of the tree is reached.
- The minimal variety of nodes turns into the leaf and is labelled as the anticipated class/worth for a specific area or attribute.
Recursive Partitioning
This top-down course of is named recursive partitioning. It is usually often known as grasping algorithm, as at every step, the algorithm picks the perfect break up primarily based on the present information. This method is environment friendly however doesn’t guarantee a generalized optimum tree.
For instance, consider a choice tree for a espresso resolution. The foundation node asks, “Time of Day?”; if it’s morning, it asks “Drained?”; if sure, it results in “Drink Espresso,” else to “No Espresso.” An analogous department exists for the afternoon. This illustrates how a tree makes sequential choices till reaching a remaining reply.
For this instance, the tree begins with “Time of day?” on the root. Relying on the reply to this, the subsequent node can be “Are you drained?”. Lastly, the leaf offers the ultimate class or resolution “Drink Espresso” or “No Espresso”.
Now, because the tree grows, every break up goals to create a pure youngster node. If splits cease early (because of depth restrict or small pattern dimension), the leaf could also be impure, containing a mixture of lessons; then its prediction stands out as the majority class in that leaf.
And if the tree grows very massive, we now have so as to add a depth restrict or pruning (that means eradicating the branches that aren’t essential) to stop overfitting and to regulate tree dimension.
Benefits and downsides of resolution bushes
Determination bushes have many strengths that make them a preferred alternative in machine studying, though they’ve pitfalls. On this part, we are going to speak about a few of the biggest benefits and downsides of resolution bushes:
Benefits
- Straightforward to know and interpret: Determination bushes are very intuitive and might be visualized as circulation charts. As soon as a tree is constructed or accomplished, one can simply see which function results in which prediction. This makes a mannequin extra clear.
- Deal with each numerical and categorical information: Determination bushes deal with each categorical and numerical information by default. They don’t require any encoding strategies, which makes them much more versatile, that means we are able to feed blended information varieties with out in depth information preprocessing.
- Captures non-linear relations within the information: Determination bushes are also referred to as they’re able to analyze and perceive the advanced hidden patterns from information, to allow them to seize the non-linear relationships between enter options and goal variables.
- Quick and Scalable: Determination bushes take little or no time whereas coaching and might deal with datasets with cheap effectivity as they’re non-parametric.
- Minimal information preparation: Determination bushes don’t require function scaling as a result of they break up on precise classes means there’s much less want to do this externally; many of the scaling is dealt with internally.
Disadvantages
- Overfitting: Because the tree grows deeper, a resolution tree simply overfits on the coaching information. This implies the ultimate mannequin will be unable to carry out nicely because of the lack of generalization on check or unseen real-world information
- Instability: The effectivity of the choice tree depends upon the node it chooses to separate the info to discover a pure node. However small modifications within the coaching set or a incorrect resolution whereas selecting the node can result in a really completely different tree. In consequence, the result of the tree is unstable.
- Complexity will increase because the depth of the tree will increase: Deep bushes with many ranges additionally require extra reminiscence and time to guage, together with the problem of overfitting, as mentioned.
Functions of Determination Timber
Determination Timber are standard in apply throughout the machine studying and information science fields because of their interpretability and suppleness. Listed below are some real-world examples:
- Advice Programs: A call tree can present suggestions to a consumer on an e-commerce or media web site by analyzing that consumer’s exercise and content material preferences primarily based on their conduct. Based mostly on all of the patterns and splits in a tree, it’s going to recommend explicit merchandise or content material that the consumer is probably going involved in. For instance, for an internet retailer, a choice tree can be utilized to categorise the product class of a consumer primarily based on their exercise on-line.
- Fraud Detection: Determination bushes are sometimes utilized in monetary fraud detection to type suspicious transactions. On this case, the tree can break up on issues like transaction quantity, transaction location, frequency of transactions, character traits and much more to categorise if the exercise is fraudulent.
- Advertising and marketing and Buyer Segmentation: The advertising groups of companies can use resolution bushes to phase or set up prospects. On this case, a choice tree could possibly be used to categorize if the shopper could be doubtless to answer a marketing campaign or in the event that they had been extra more likely to churn primarily based on historic patterns within the information.
These examples show the broad use case for resolution bushes, they can be utilized in each classification and regression duties in fields various from advice algorithms to advertising to engineering.
Hey! I am Vipin, a passionate information science and machine studying fanatic with a powerful basis in information evaluation, machine studying algorithms, and programming. I’ve hands-on expertise in constructing fashions, managing messy information, and fixing real-world issues. My objective is to use data-driven insights to create sensible options that drive outcomes. I am wanting to contribute my expertise in a collaborative surroundings whereas persevering with to be taught and develop within the fields of Information Science, Machine Studying, and NLP.
Login to proceed studying and revel in expert-curated content material.